ChatGPT能否取代Google、百度这样的传统搜索引擎?为什么中国不能很快做出ChatGPT?当前,对这些问题的探讨大多囿于大型语言模型的技术可行性,忽略或者非常粗糙地估计了实现这些目标背后的经济成本,从而造成对LLM的开发和应用偏离实际的误判。
本文作者从经济学切入,详细推导了类ChatGPT模型搜索的成本、训练GPT-3以及绘制LLM成本轨迹的通用框架,为探讨LLM成本结构和其未来发展提供了可贵的参考视角。
重点概览:
LLM驱动的搜索已经在经济上可行:粗略估计,在现有搜索成本结构的基础上,高性能LLM驱动搜索的成本约占当下预估广告收入/查询的15%。但经济可行并不意味着经济合理:LLM驱动搜索的单位经济性是有利可图的,但对于拥有超1000亿美元搜索收入的现有搜索引擎来说,添加此功能可能意味着超100亿美元的额外成本。其他新兴的LLM驱动业务利润很高:比如Jasper.ai使用LLM生成文案,很可能有SaaS服务那样的毛利率。对于大公司而言,训练LLM的成本并不高:如今,在公有云中训练GPT-3仅需花费约140万美元,即使是像PaLM这样最先进的模型也只需花费约1120万美元。LLM的成本可能会显著下降:自GPT-3发布的两年半时间里,与GPT-3性能相当的模型的训练和推理成本下降了约80%。数据是LLM性能的新瓶颈:与增加高质量训练数据集的大小相比,增加模型参数的数量能获得的边际收益越来越小。
#01
动机
LLM的惊人表现引发了人们的广泛猜想,这些猜想主要包括LLM可能引发的新兴商业模式和对现有模式的影响。
搜索是一个有趣的机会,2021年,仅谷歌就从搜索相关的广告中获得了超1000亿美元的收入。ChatGPT的“病性”传播已经引发了许多关于搜索领域潜在影响的思考,其中一个就是LLM如今的经济可行性:
一位声称是谷歌员工的人在HackerNews上表示,要想实施由LLM驱动的搜索,需要先将其成本降低10倍。与此同时,微软预计将在3月份推出LLM版本的Bing,而搜索初创公司如You.com已经将该技术嵌入到了他们的产品之中。最近,《纽约时报》报道,谷歌将在今年推出带有聊天机器人功能的搜索引擎。更广泛的问题是:**将LLM纳入当前产品和新产品的经济可行性如何?**在本文中,我们梳理了当今LLM的成本结构,并分析其未来可能的发展趋势。
#02
重温LLM工作原理
尽管后续章节的技术性更强,但这篇文章对机器学习熟悉程度不做要求,即使不熟悉这方面内容的人也可以放心阅读。为了说明LLM的特殊之处,现做一个简要复习。
语言模型在给定上下文的情况下,对可能输出的token作出预测:

自回归语言模型输入上下文和输出内容的图示
为了生成文本,语言模型根据输出token的概率重复采样新token。例如,在像ChatGPT这样的服务中,模型从一个初始prompt开始,该prompt将用户的查询作为上下文,并生成token来构建响应。新token生成后,会被附加到上下文窗口以提示下一次迭代。
稳定币crvUSD科普创新清算机制LLAMMA,可在抵押品价格下跌时逐步替换为稳定币:1月17日消息,Curve官方科普其稳定币crvUSD创新的清算机制LLAMMA,解释了LLAMMA通过AMM的特性进行针对债务人更友善的清算方式,让抵押品在价格下跌时逐渐转移成稳定币,让原本要清偿的债务有一定程度的稳定币可以偿还,同时在价格回稳时再逐渐把稳定币换回抵押品,而不是直接的触发清算导致债务人的亏损。
此前报道,2022年11月23日,去中心化交易平台CurveFinance开发者发布Curve即将推出的去中心化Stablecoin“crvUSD”的官方代码和白皮书。[2023/1/17 11:17:13]
语言模型已经存在了几十年。当下LLM性能的背后是数十亿参数的高效深度神经网络驱动。参数是用于训练和预测的矩阵权重,浮点运算的数值通常与参数数量成比例。这些运算是在针对矩阵运算优化的处理器上计算的,例如GPU、TPU和其他专用芯片。
随着LLM参数量呈指数增长,这些操作需要更多的计算资源,这是导致LLM成本增加的潜在原因。
#03
LLM驱动搜索的成本
本节,我们将估算运行LLM驱动搜索引擎的成本。应该如何实施这样的搜索引擎仍是一个活跃的研究领域,我们这里主要考虑两种方法来评估提供此类服务的成本范围:
ChatGPTEquivalent:一个在庞大训练数据集上训练的LLM,它会将训练期间的知识存储到模型参数中。在推理过程中,LLM无法访问外部知识。容易“幻想”事实。模型知识滞后,仅包含最后训练日期之前的可用信息。??以上两点,是这种方法存在的两大缺陷。2-StageSearchSummarizer:一种架构上类似的LLM,可以在推理时访问Google或Bing等传统搜索引擎。在这种方法的第一阶段,我们通过搜索引擎运行查询以检索前K个结果。在第二阶段,通过LLM运行每个结果以生成K个响应,该模型再将得分最高的响应返回给用户。能够从检索到的搜索结果中引用其来源。能获取最新信息。相比ChatGPTEquivalent,这种方法的优点是:然而,对于相同参数数量的LLM,这种方法需要更高的计算成本。使用这种方法的成本也增加了搜索引擎的现有成本,因为我们在现有搜索引擎的结果上增加了LLM。
一阶近似:基础模型API
最直接的成本估算方法是参考市场上现有基础模型API的标价,这些服务的定价包括成本的溢价部分,这部分是供应商的利润来源。一个代表性的服务是OpenAI,它提供基于LLM的文本生成服务。
OpenAI的DavinciAPI由GPT-3的1750亿参数版本提供支持,与支持ChatGPT的GPT-3.5模型具有相同的参数数量。现在用该模型进行推理的价格约为0.02美元/750个单词;用于计算定价的单词总数包括输入和输出。
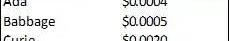
按模型功能划分的基础模型API定价(OpenAI)
我们这里做了一些简单假设来估计将支付给OpenAI的搜索服务费用:
徐明星新书《趣说金融史》正式发布 科普金融发展之道:金色财经现场报道,9月23日,欧科云链创始人徐明星携手著名财经作家李霁月、行业观察者顾泽辉力作《趣说金融史》一书,跨越5000年金融历史,重读金钱故事,并预测新的金融时代。该书由中信出版社出版,将于近期正式发售。据了解,本书可以更好地呈现金融的起源与发展,帮助人们理解货币、金融与未来经济。作为区块链行业领军企业——欧科云链的创始人,徐明星深知技术探索对经济社会的重要推动作用,他曾先后出版过《图说区块链》、《区块链:重塑经济与世界》、《通证经济》、《链与未来》等行业权威著作,解读区块链等新型技术的推动下,金融与社会的升级之道,对经济社会发展做出了重大贡献。其中,《区块链:重塑经济与世界》曾作为新中国70周年重点推荐图书之一被相关书店推荐。[2021/9/23 17:00:57]
在ChatGPTequivalent的实现中,我们假设该服务平均针对50字的prompt生成400字的响应。为了产生更高质量的结果,我们还假设模型对每个查询采样5个响应,从中选择最佳响应。因此:
在2-StageSearchSummarizer的实现中,响应生成过程是相似的。然而:
提示明显更长,因为它同时包含查询和搜索结果中的相关部分为每K个搜索结果生成一个单独的LLM响应假设K=10并且搜索结果中的每个相关部分平均为1000个单词:

假设优化的缓存命中率为30%和OpenAI云服务的毛利率为75%,我们的一阶估计意味着:

按照数量级,ChatGPTEquivalent服务的预计云计算成本为0.010美元/次,与公众评论一致:
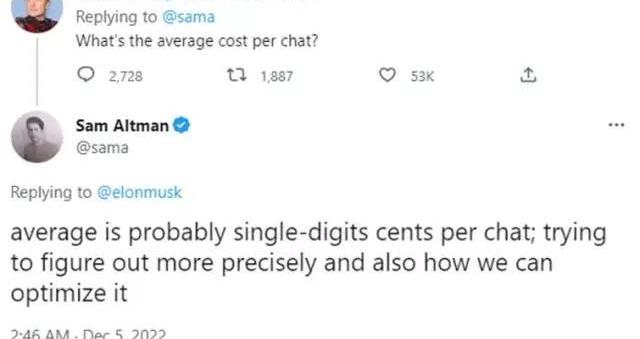
OpenAI首席执行官SamAltman谈ChatGPT每次聊天的成本鉴于ChatGPTEquivalent的上述缺点,在实际操作中,LLM驱动搜索引擎的开发者更可能部署2-StageSearchSummarizer变体。
2012年,谷歌搜索主管表示,其搜索引擎每月处理的搜索次数达1000亿次。世界银行数据显示:全球互联网普及率已从2012年的34%上升到了2020年的60%。假设搜索量按比例增长,则预计其年均搜索量将达2.1万亿次,与搜索相关的收入将达约1000亿美元,平均每次搜索的收入为0.048美元。
换句话说,2-StageSearchSummarizer的查询成本为0.066美元/次,约为每次查询收入0.048美元的1.4倍。
人大附中物理老师李永乐科普拜占庭将军问题和区块链:5月14日,人大附中物理老师、科普视频网红李永乐在其公众号发布视频《拜占庭将军问题是什么?区块链如何防范恶意节点?》。李永乐老师在视频中对拜占庭将军问题和区块链进行了讲解,他表示,拜占庭将军问题本质上指的是,在分布式计算机网络中,如果存在故障和恶意节点,是否能够保持正常节点的网络一致性问题。在近40年的时间里,人们提出了许多方案解决这一问题,称为拜占庭容错法。例如兰波特自己提出了口头协议、书面协议法,后来有人提出了实用拜占庭容错PBFT算法,在2008年,中本聪发明比特币后,人们又设想了通过区块链的方法解决这一问题。区块链通过算力证明来保持账本的一致性,也就是必须计算数学题,才能得到记账的权力,其他人对这个记账结果进行验证,如果是对的,就认可你的结果。与拜占庭问题比起来,就增加了叛徒的成本。[2020/5/14]
通过以下优化,预估成本大约会降至原来的1/4:1、量化2、知识蒸馏3、训练更小的“计算优化”模型,该模型具有相同的性能假设云计算的毛利率约为50%,与依赖云服务提供商相比,运行自建基础设施会使成本降低至当前的1/2。综合以上改进,降低至原有成本的1/8之后,在搜索中融入高性能LLM的成本大约占据当前查询收入的15%。深度解析:云计算成本
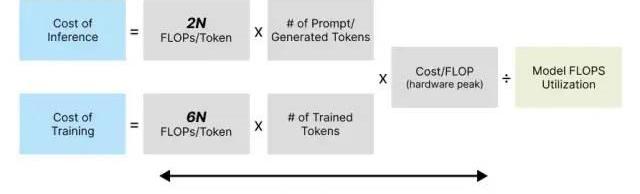
如今,SOTA大型语言模型通常会用到可比较的模型架构,在推理过程中每个token的计算成本约为2N,其中N为模型参数数量。
目前,NVIDIAA100是AWS最具成本效益的GPU选择,若预定1年使用该GPU,拥有8个A100的AWSP4实例的有效时薪将达19.22美元。每个A100提供峰值312TFLOPSFP16/FP32混合精度吞吐量,这是LLM训练和推理的关键指标。FP16/FP32混合精度是指以16位格式执行操作,而以32位格式存储信息。由于FP16的开销较低,混合精度不仅支持更高的FLOPS吞吐量,而且保持精确结果所需的数值稳定性也会保持不变。
假设模型的FLOPS利用率为21.3%,与训练期间的GPT-3保持一致。因此,对于像GPT-3这样拥有1750亿参数的模型:

我们也应用了基于GCPTPUv4定价相同的计算方法,并得到了相似的结果:
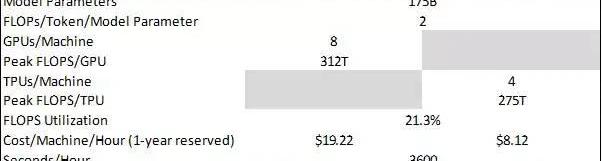
预估GPT-3通过云服务提供商(AWS,?GCP)每处理1000个token所需的推理成本
OpenAI的API定价为0.02美元/1000词,但我们估计其成本约为0.0035美元/1000词,占定价的20%左右。这就意味着:**对于一台一直运行的机器而言,其毛利率约为80%。**这一估算与我们之前设想的75%毛利率大致相同,进而为ChatGPTEquivalent和2-StageSearchSummarizer搜索成本估算提供了合理性验证。
#04
声音 | CNBC主持人:加密货币最大的缺点之一就是难以向外行快速科普:CNBC主持人Ran NeuNer近期发推称,加密货币最大的缺点之一就是很难向外行快速解释。当人们要求我向他们解释比特币时,我知道他们至少需要一个小时才能真正理解。[2019/9/10]
训练成本如何?
另一个热门话题是GPT-3或最新的LLM的训练成本。基于参数数量和token数量,我们构建了一个用于估算计算成本的框架,虽然稍作修改,但同样适用于此:
每个token的训练成本通常约为6N,其中N是LLM的参数数量假设在训练过程中,模型的FLOPS利用率为46.2%,与在TPUv4芯片上进行训练的PaLM模型一致。1750亿参数模型的GPT-3是在3000亿token上进行训练的。谷歌使用了GCPTPUv4芯片来训练PaLM模型,若我们现在也像谷歌那样做,那么如今的训练成本仅为140万美元左右。

此外,我们还将该框架应用到一些更大的LLM模型中,以了解其训练成本。

预估LLM在GCPTPUv4芯片上的训练成本
#05
绘制成本轨迹的通用框架
为了推导LLM的推理成本/训练成本,我们总结了如下框架:

密集激活纯解码器LLM模型Transformer的推理成本和训练成本
因此,我们假设LLM的架构相似,那么推理成本和训练成本将根据上述变量的变化而变化。虽然我们会详细考虑每个变量,但是以下部分才是关键点:
自2020年GPT-3发布以来,使用与GPT-3一样强大的模型进行训练和推理的成本大大降低,低于先前的五分之一。

相比2020年推出的GPT-3,与其性能对等的模型的推理与训练成本降低情况总结
参数数量效率:巨型语言模型参数每年增长10倍的神话
考虑到过去5年中模型参数呈指数增长,我们普遍猜测:下一代LLM模型很可能是万亿参数模型:

LLM中模型参数数量的增长
虽然LLM的参数数量每年约增长10倍,但是大多数模型训练数据集的大小并没有显著变化:

动态 | 浙江卫视节目科普支付宝区块链防伪溯源产品:昨日,在浙江卫视播出的科普综艺栏目《智造将来》现场,支付宝首次展示了支付宝区块链防伪溯源产品,以接地气的方式公开向大众展示区块链在生活中的应用。[2019/3/4]
所选LLM的模型参数数量与训练token数量(训练计算最优大语言模型)
然而,最新文献表明,假设计算资源和硬件利用率保持不变,关注扩展参数数量并不是性能最大化的最佳方式:

GoogleDeepMind的研究人员将一个参数函数拟合到他们的实验结果中,发现参数数量N的增速应与训练token数量D的增长速度大致相同,从而让模型损失L实现最小化:
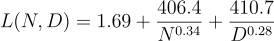
模型损失的参数函数(训练计算最优大语言模型)
研究人员还训练了一个名为Chinchilla的模型。虽然该模型的计算资源与Gopher相同,但是该模型是在1.4万亿token上进行训练的而非3000亿token。Chinchilla的性能明显优于拥有相同FLOPs预算的大型模型,从而证明了大多数LLM过度支出了计算量和对数据的渴望。

通过训练数据大小与模型参数来预测模型损失(错误更少:Chinchilla的自然环境含义)
虽然Chinchilla的参数比GPT-3少60%,但是其性能远远优于拥有1750亿参数的GPT-3模型。实际上,即使我们用与GPT-3相同的3000亿token数据集去训练一个万亿参数模型,仍可以预见该模型的表现不如Chinchilla:
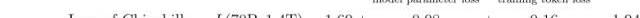
万亿参数模型相应损失项的相对量级也表明,通过增加模型大小获得的边际效益低于增加数据量获得的边际效益。
展望未来,我们不会继续扩大模型参数数量,而是将增量计算资源转移到质量相当的更大数据集上进行训练,以获得极佳的性能。Cost/FLOP效率
对于训练LLM而言,最重要的硬件性能指标是可实现的混合精度FP16/FP32FLOPS。改进硬件旨在实现成本最小化,同时使得峰值FLOPS吞吐量和模型FLOPS利用率实现最大化。
虽然这两个部分在硬件开发中密不可分,但为了让分析变得更简单,本节重点关注吞吐量,下一节再讨论利用率。
目前,我们已经通过查看云实例定价估算了Cost/FLOP效率。为了进行下一步探究,我们估算了运行以下机器的成本。主要包括以下两个方面:1)硬件购买2)能源支出。为说明这一点,我们再来看看GPT-3(一款由OpenAI推出的模型,该模型在MicrosoftAzure的10000个V100GPU上训练了14.8天):

2020年用英伟达V100GPU训练GPT-3的成本(碳排放与大型神经网络训练)
黄仁勋定律指出,在硬件成本方面,GPU的增长速度比五年前快了25倍。在训练LLM的背景下,GPU的性能得到了很大提升,这很大程度上得益于张量核心)。此外,GPU不再将矢量作为计算原语,而是转为矩阵,从而实现了性能更好、效率更高的混合精度计算。
2016年,NVIDIA通过V100数据中心GPU首次推出了张量核心。与最初引入的张量核心相比,虽然这一改进不太明显,但是每一代张量核心都进一步提高了吞吐量。如今,对于用于训练LLM的数据中心GPU,我们仍能看到每一代GPU的吞吐量都提升了50%。

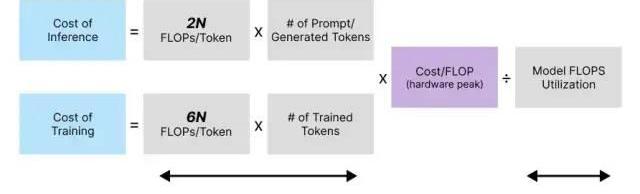
数据中心GPUFP16/FP32吞吐量/美元(NVIDIA)
桌面GPU和数据中心GPU、按精度划分的吞吐量/美元(英伟达,深度学习推理中的计算和能源消耗趋势)
桌面GPU和数据中心GPU、按精度划分的吞吐量/美元(英伟达,深度学习推理中的计算和能源消耗趋势)
能源效率提升得更快。现在我们可以看到,用于训练LLM的数据中心GPU的代际吞吐量/瓦特提高了80%:

数据中心GPUFP16/FP32吞吐量/瓦特(英伟达)
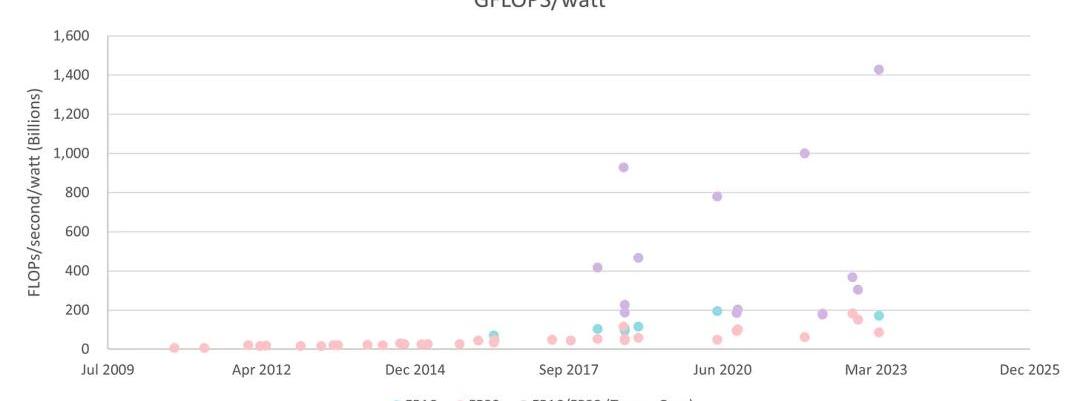
按精度划分的桌面和数据中心GPU吞吐量/瓦特
仅从V100到即将推出的H100的改进来看,我们预计内部训练成本将降低58%。

目前使用英伟达H100GPU训练GPT-3的成本
展望未来,我们预测,**随着硬件设计的不断创新,硬件成本和能效将逐步改进。**例如,从V100到A100GPU,NVIDIA添加了稀疏特性,这进一步将某些深度学习架构的吞吐量提高了2倍。NVIDIA正在H100中添加对FP8数据类型的本地支持,当与推理量化等现有技术相结合时,可以进一步提高吞吐量。
此外,TPU和其他专用芯片的出现从根本上重塑了深度学习用例的芯片架构。谷歌的TPU建立在脉动阵列结构之上,可显著减少寄存器使用,提高吞吐量。正如下一节将提到的,随着我们将训练和推理扩展到大型参数模型,最近许多硬件都着力于提高利用率。
硬件利用率提升
出于内存需求,LLM训练的主要挑战之一就是将这些模型从单个芯片扩展到多个系统和集群级别。在典型的LLM训练中,设置保存优化器状态、梯度和参数所需的内存为20N,其中N是模型参数数量。
因此,BERT-Large仅需6.8GB内存,就可轻松装入单个桌面级GPU。另一方面,对于像GPT-3这样的1750亿参数模型,内存要求转换为3.5TB。同时,NVIDIA最新的数据中心GPU仅包含80GB的高带宽内存(HBM),这表明至少需要44个H100才能满足GPT-3的内存要求。此外,即使在10000个V100GPU上训练GPT-3也需要14.8天。
因此,即使我们增加用于训练的芯片数量,FLOPS利用率也仍然需要保持高水平,这一点至关重要。
**硬件利用率的第一个维度是在单芯片层面。**在单个A100GPU上训练GPT-2模型时,硬件利用率达35.7%。事实证明,片上内存和容量是硬件利用的瓶颈之一:处理器内核中的计算需要重复访问HBM,而带宽不足会抑制吞吐量。同样,有限的本地内存容量会迫使从延迟较高的HBM进行更频繁的读取,从而限制吞吐量。
硬件利用率的第二个维度与芯片到芯片的扩展有关。训练像GPT-3这样的LLM模型需要跨多个GPU对模型和数据进行划分。正如片上存储器的带宽可能成为硬件利用的瓶颈一样,芯片间互连的带宽也可能成为硬件利用的限制因素。随着V100的发布,NVIDIA的NVLink实现了每个GPU300GB/s的带宽。对于A100来说,宽带速度实现了600GB/s。
硬件利用率的最后一个维度是系统到系统的扩展。一台机器最多可容纳16个GPU,因此扩展到更多数量的GPU要求跨系统的互连不能成为性能瓶颈。为此,Nvidia的InfinibandHCA在过去3年中将最大带宽提高了2倍。
在第二和第三个维度上,软件划分策略是硬件有效利用的关键考虑因素。通过结合模型和数据并行技术,2022年使用MT-NLG的Nvidia芯片集群级别的LLM训练的模型FLOPS利用率达到了30.2%,而使用GPT-3的模型FLOPS利用率在2020年只有21.3%:
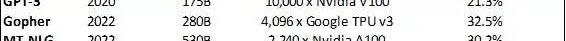
选择LLM的模型FLOPS利用率
选择LLM的模型FLOPS利用率
TPU等专用硬件实现了更高的效率。
谷歌5400亿参数的PaLM模型在TPUv4芯片上实现了46.2%的模型FLOPS利用率,是GPT-3训练利用率的2.2倍FLOPS利用率的提高得益于更高效的并行训练以及从根本上TPU具有完全不同的架构。该芯片的脉动阵列结构和每个内核的显著的本地内存密度降低了高延迟全局内存的读取频率。
同样地,我们可以看到**Cerebras、Graphcore**和SambaNova等公司在处理器中分配了更多的共享内存容量。展望未来,我们预计其他新兴创新,例如将芯片扩展到晶圆级以减少延迟/增加带宽,或通过可编程单元优化数据访问模式等将进一步推动硬件利用率的发展。
#06
大型语言模型即将迎来全盛时期
据《纽约时报》近日报道,谷歌宣称ChatGPT是其搜索业务的“红色警报”,它的搜索量呈病式发展。
从经济角度来看,通过粗略估算,将高性能LLM纳入搜索将花费约15%的查询收入,这表明该技术的部署已经切实可行。然而,谷歌的市场主导地位阻碍了它成为这方面的先行者:谷歌目前的搜索收入为1000亿美元,将高性能LLM纳入搜索会使谷歌的盈利能力减少一百多亿美元。
另一方面,也就难怪微软会计划将大语言模型纳入Bing了。尽管LLM支持的搜索成本高于传统搜索,并且与谷歌相比,微软搜索引擎的市场份额要低得多,但是微软并未亏损。因此,如果微软能够成功地从谷歌手中夺取搜索市场份额,那么即使现有查询成本更高,微软仍然能够获得极高的利润。
有趣的是,对于其他产品,通过部署LLM已经可以通过SaaS来盈利。例如,最近估值为15亿美元、使用LLM生成文案的Jasper.ai收费为82美元/100000字。使用OpenAI的DavinciAPI定价为0.02美元/1000个token,即使我们对多个响应(response)进行采样,毛利率也可能远高于75%。
同样令人惊讶的是,如今在公有云中仅需约140万美元即可对GPT-3进行训练,而且即使是SOTA模型的训练成本也不会太高。在过去的两年半里,类似GPT-3等模型的训练成本下降了80%以上,高性能大语言模型的训练成本将进一步降低。
换句话说,训练大语言模型并不便宜,但也没那么烧钱,训练大语言模型需要大量的前期投入,但这些投入会逐年获得回报。更近一步,Chinchilla论文表明,在未来,相比资金,高质量数据会成为训练LLM的新兴稀缺资源之一,因为扩展模型参数数量带来的回报是递减的。
标签:NFTAPYTOKENISCGalactic Arena: The NFTverseHAPYAK12 Tokengenesischain
摘要:1.$CRV的代币经济保护Curve建立了较高的竞争壁垒。2.Curve的“流动性即服务”——解决链上流动性需求的功能.
加密行业的黑暗森林危机四伏,暗藏着各式各样的危机与陷阱,资产被盗的剧情经常上演,热门赛道NFT和知名玩家们亦不能幸免.
大多数蓝筹在近一个月都迎来不同程度上涨自FTX暴雷后,加密市场的情绪在这起事件的阴霾中持续低落,NFT市场也不例外.
摘要 l?中本聪在2009年创造比特币的时候,就有了关于支付通道的想法,并在Bitcoin1.0中包含了支付通道的代码草稿.
赚钱是加密行业的基本需求。加密市场中超过95%的参与者来这里的唯一目的就是赚钱。越快越好,越多越好。帮助人们赚钱的项目满足这一基本需求。它们最有可能在熊市中生存,而在牛市中茁壮成长.
在经历了数月猜测之后,美国当地时间周四深夜,作为FTX崩盘的最新受害者,加密借贷公司Genesis正式向曼哈顿联邦法院申请第11章破产保护.