来源:阿尔法工场
最近,正在进行AI大战的各个大厂,被谷歌泄漏的一份内部文件,翻开了窘迫的一面。
这份泄露的内部文件声称:“我们没有‘护城河’,OpenAI也没有。当我们还在争吵时,第三个方已经悄悄地抢了我们的饭碗——开源。”
这份文件认为,现在的一些开源模型,一直在照搬谷歌、微软这些大厂的劳动成果,并且双方差距正在以惊人的速度缩小。开源模型更快、可定制性更强、更私密,而且功能性也不落下风。
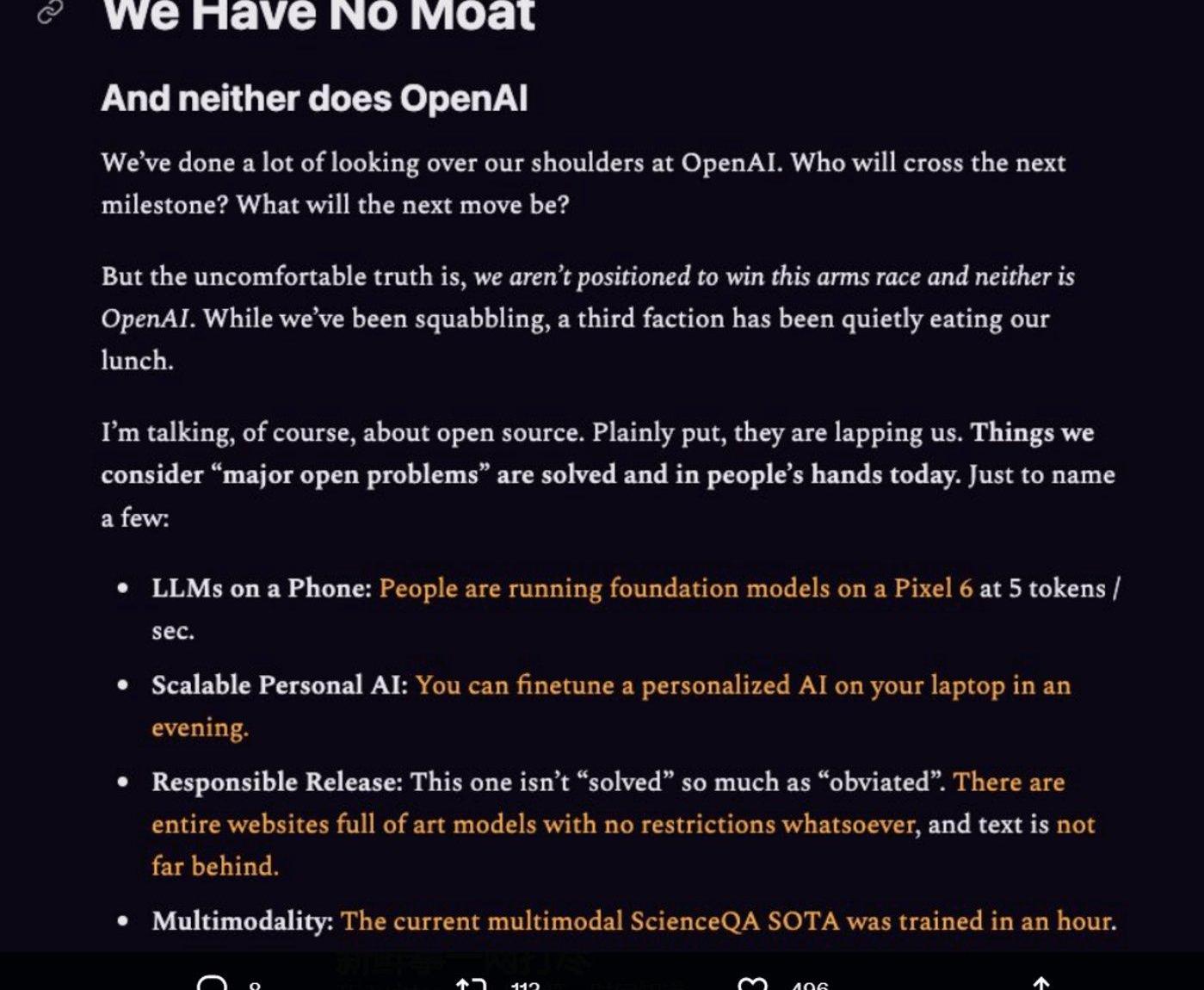
比如,这些开源模型可以用100美元外加13B参数,加上几个礼拜的时间就能出炉,而谷歌这样的大厂,要想训练大模型,则需要面对千万美元的成本和540B参数,以及长达数月的训练周期。
那么,事实是否真的像这份文件所说的那样,谷歌和OpenAI在AI方面的种种积累,最终真的会败给一群隐藏在民间的“草头侠”?
所谓“大厂垄断大模型”的时代,真的要终结了吗?
要回答这个问题,我们就得先了解下目前开源模型的生态,看看这些如雨后春笋般涌现的开源模型,究竟是如何一步步蚕食谷歌这些“正规军”的江山的。
律师:FTX的“大量”资产不是被偷就是失踪:金色财经报道,FTX的一位律师对破产法庭表示,相当数量的FTX Group资产要么被盗,要么不见了。Sullivan & Cromwell的律师James Bromley周二告诉法官。很遗憾债务人FTX的经营状况不是特别好,这已经是个保守的说法了。Bromley说,SBF打造的FTX加密货币帝国垮台非常迅速,令人极其震惊。他用史无前例来形容这宗破产案。Bromley在法庭上表示,一旦SBF签署转让控制权的文件,每个人都第一次意识到“皇帝其实没穿衣服”,FTX可能很快就会请求法官批准其出售部分资产。[2022/11/23 7:58:51]
01异军突起的开源模型
其实,最早的开源模型,其诞生完全是一场“偶然”。
今年2月,Meta发布了自家的大型语言模型LLaMA,参数量从70亿到650亿不等,并仅用130亿的参数,就在大多数基准测试下超越了GPT-3。
但万万没想到的是,刚发布没几天,LLaMA的模型文件就被泄露了。
至此之后,开源模型的浪潮就如决堤一般,变得一发不可收拾。
欧洲央行管委雷恩:欧洲央行将在9月采取“大幅度”的利率行动:8月28日消息,欧洲央行管委雷恩表示,现在是欧洲央行行动起来抗击通胀的时机,欧元汇率是欧洲央行决策的重要考量因素。并表示,还没到公开讨论量化紧缩的时候,欧洲央行的下一步举措是在9月采取“大幅度”的利率行动,而现在正持续有序地实施货币政策正常化。(金十)[2022/8/28 12:53:46]
如八仙过海一般的ChatGPT开源替代品——「羊驼家族」,随即粉墨登场。
与ChatGPT这类大模型相比,此类开源模型最显著的特点,就是训练成本与时间都极其低廉。
以LlaMA的衍生模型Alpaca为例,其训练成本仅用了52k数据和600美元。
然而,如果开源光靠低成本,还不足以让谷歌这类大厂感到威胁,重要的是,在极低的训练成本下,这些开源模型还能屡次达到和GPT-3.5匹敌的性能。
这下谷歌和OpenAI就坐不住了。
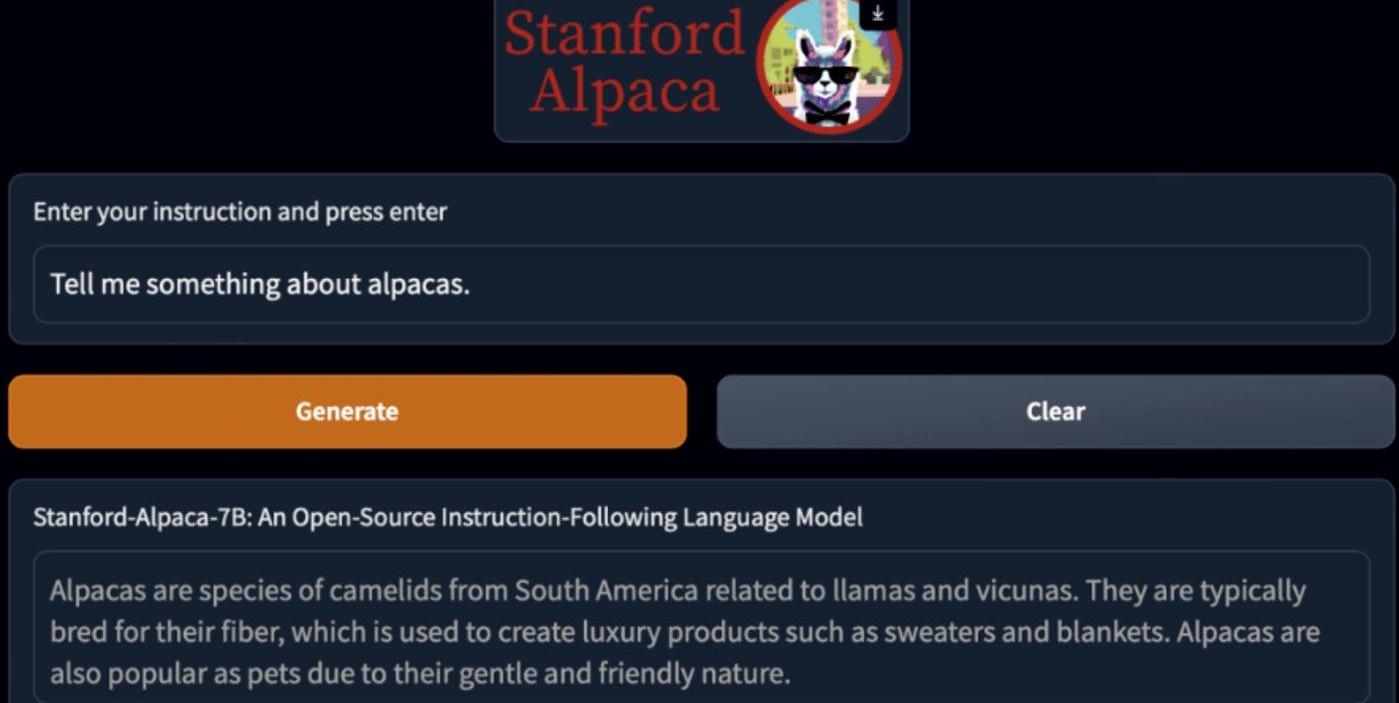
斯坦福研究者对GPT-3.5和Alpaca7B进行了比较,发现这两个模型的性能非常相似。Alpaca在与GPT-3.5的比较中,获胜次数为90对89。
“大空头”MichaelBurry:SEC缺乏调查 Coinbase的“智商点”:金色财经报道,针对彭博社发表的题为 \"Coinbase面临SEC对加密货币上市的调查 \"的报道,《大空头》作者Michael Burry在7月26日的推特上对这篇文章进行了评论。Burry表示,很确定SEC没有资源或智商点来正确地做这件事。[2022/7/29 2:44:46]
重点来了:这些开源模型,究竟是怎么做到这点的?
斯坦福团队的答案是两点:1、一个强大的预训练语言模型;2、一个高质量的指令遵循数据。
在这里,我们将强大的预训练语言模型,比喻为一位有着丰富知识和经验的老师。
对于自然语言处理领域的任务,强大的预训练语言模型,可以利用大规模的文本数据进行训练,学习到自然语言的模式和规律,并且可以帮助指令遵循等任务的模型更好地理解和生成文本,提高模型的表达和理解能力。
这就相当于学生使用老师的知识和经验,来提高语言能力,指令遵循等任务的模型可以使用预训练语言模型的知识和经验来提高自己的表现。
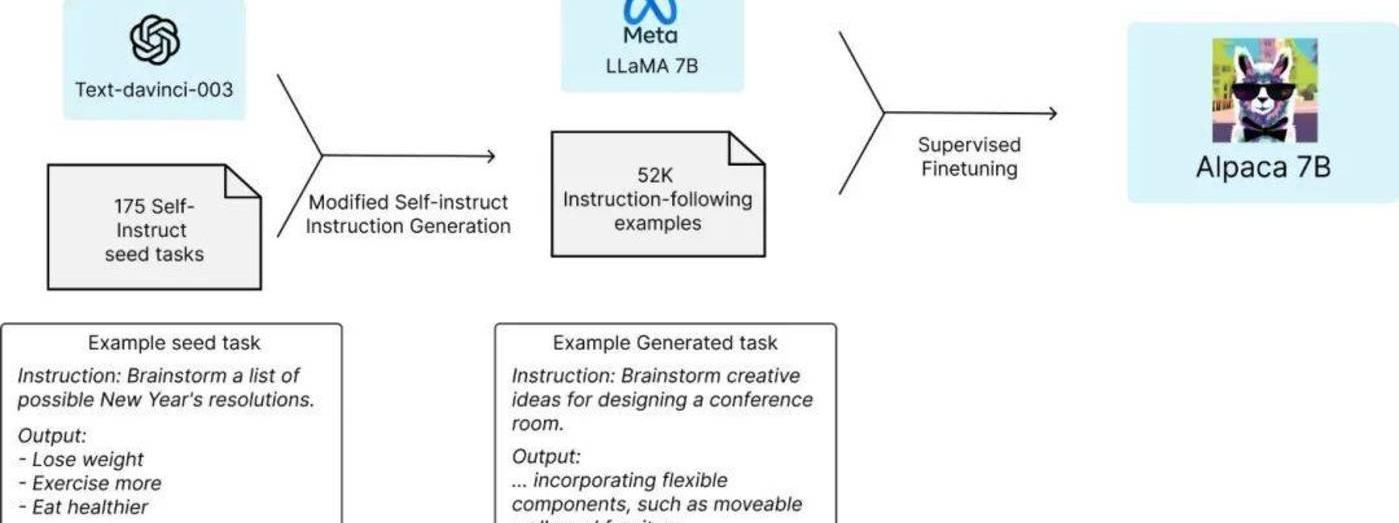
除了借助这位“老师”的知识外,开源模型的另一“利刃”,就是指令微调。
人大代表陈建华:建议出台“大数据法”维护数据权益:全国人大代表、人民银行石家庄中心支行行长陈建华今年带来的提案和大数据有关。他建议,从立法层面出台《大数据法》,对不同类型数据的采集、处理、存储、分析、使用、共享等各个环节制定专业清晰的法律法规,维护全链条数据权益,确保大数据安全可靠,保证大数据应用生态良好,发挥大数据最大作用和价值,体现国家治理的法治精神。(财联社)[2020/5/21]
指令微调,或指令调优,是指现有的大语言模型生成指令遵循数据后,对数据进行优化的过程。
具体来说,指令微调是指在生成的指令数据中,对一些不合适或错误的指令进行修正,使其更符合实际应用场景。
而指令调优是指在生成的指令数据中,对一些重要、复杂或容易出错的指令进行加重或重复,以提高指令遵循模型对这些指令的理解和表现能力。
凭借着这样的“微调”,人们可以生成更准确、更有针对性的指令遵循数据,从而提高开源模型在特定任务上的表现能力。
如此一来,即使只用很少的数据,开源社区也能训练出性能匹敌ChatGPT的新模型。
然而,又一个问题是:面对自己辛苦打下的江山,被开源社区用“四两拨千斤”的方式步步蚕食,谷歌和OpenAI为何一直没有予以反制呢?
哪怕是如法炮制,以攻,推出同样快速迭代的小模型,也不失为一种破局之策啊。
韩媒:韩国ICO禁令并未生效,或将出现“大逆转”:《韩国日报》援引知情人士称,韩国金融当局可能允许国内投资者进行ICO,旨在发展区块链技术。某匿名消息人士指出,金融当局正在与税务机构、司法部及其它相关政府部门讨论关于允许在国内ICO的计划,前提是要满足一些特定条件。该项计划一旦实施将会是去年9月韩国政府ICO禁令的大逆转。此外,尽管韩国政府宣布禁止国内ICO活动,但其并未实施具体规则,也没有强制公司进行ICO清退。国内投资者仍然能够参与国外ICO,同样能在数字货币交易所进行交易。[2018/3/12]
02骑虎难下
实际上,谷歌这样的头部企业,不是没有意识到开源的优势。
在那份泄漏的文件中,谷歌就提到:几乎任何人都能按照自己的想法实现模型微调,到时候一天之内的训练周期将成为常态。以这样的速度,微调的累积效应将很快帮助小模型克服体量上的劣势。
可问题是,身为AI领域巨头的谷歌和OpenAI,既不能,也不愿完全放弃训练成本高昂的大参数模型。
从某种程度上说,这是其保证自身优势地位的必要手段。
作为AI领域的巨头,谷歌和OpenAI需要不断提升自己的技术实力和创新能力。而传统的大参数训练模型,则是提供这一探索和创新的必经之路。
因为大模型的底层技术若想取得突破,AI领域的研究者和科学家,就需要更深入地理解模型和算法的基本原理,探索AI技术的局限性和发展方向,这需要进行大量的理论研究、实验验证和数据探索,而不仅仅是微调和优化。
例如,在训练大参数模型时,AI领域的科学家,可以探索模型的泛化能力和鲁棒性,在不同的数据集和场景下评估模型的性能和效果。谷歌的BERT模型,也正是在此过程中得到了不断强化。
同时,大参数模型的训练,还可以帮助科学家探索模型的可解释性和可视化,
例如,对今天的GPT来说至关重要的Transformer模型,虽然在性能上表现出色,但其内部结构和工作原理却相对复杂,不利于理解和解释。
通过大参数模型的训练,人们可以可视化Transformer模型的内部结构和特征,从而更好地理解模型是如何对输入进行编码和处理的,并进一步提高模型的性能和应用效果。
因此,开源和微调的方式,虽然可以促进AI技术的快速发展和优化,但不足以替代对AI基础问题的深入研究和探索。
但话说到这,一个十分尖锐的矛盾又摆了出来:一方面,谷歌和OpenAI不能放弃对大参数模型的研究,并坚持对其技术进行保密。但另一方面,免费、高质量的开源替代品,又让谷歌等大厂的“烧钱”策略难以为继。
因大模型耗费的巨大算力资源和数据,仅是在2022年,OpenAI总计花费就达到了5.4亿美元,与之形成鲜明对比的,则是其产生的收入只有2800万美元。
与此同时,开源社区的具有的灵活性上的优势,也让谷歌等大厂感到难以匹敌。
在那份泄漏的文件中,谷歌就认为:开源阵营真正的优势在于“个人行为”。
相较于谷歌这些大厂,开源社区的参与者可以自由地探索和研究技术,不受任何限制和压力,从而有更多机会发现新的技术方向和应用场景。
而谷歌研究和开发新技术时,则必须考虑产品的商业可行性和市场竞争力。这就对人才的研究方向产生了一定的限制和约束。
此外,由于保密协议的存在,谷歌的人才也难以像开源社区那样,与外界充分地交流和分享技术研究的成果。
如果说,低价、灵活的开源模型,终将成为一种不可阻挡的趋势,那么当谷歌等大厂面对这浩瀚的战场时,又该怎样在新时代生存下去呢?
03另辟蹊径
倘若谷歌这样的头部企业,最终在开源阵营的攻势下,选择了“打不过就加入”的策略,那如何在开源的情况下,找到一条可行的商业路径,就成了一件头等大事。
毕竟,在目前的市场认知下,开源几乎就等于“人人皆可免费使用。”
之前,StableDiffusion背后的明星公司——StabilityAI,就因为在开源后,没有找到明确的盈利途径,目前正面临严重的财政危机,以至于到了快倒闭的地步。
不过,关于如何在开源的情况下实现盈利,业界也不是完全没有先例可循。
例如,之前谷歌对Android系统的开源,就是一个经典的案例。
当年,由谷歌主导开发和推广的Android系统开源后,谷歌仍然通过各种途径,从Android操作系统的设备制造商那里获取了收益。
具体来说,这些途径可分为以下几种:
1.收取授权费用:当设备制造商希望在其设备上预装GooglePlay商店等谷歌应用和服务时,他们需要遵守谷歌的授权协议,并支付相应的授权费用。
2.推出定制设备:谷歌通过与设备制造商合作,推出一些定制的Android设备,如GooglePixel智能手机和GoogleNexus平板电脑等,并从中获得收入。这些定制设备通常具有更高的价值和更好的性能,而且会预装谷歌的应用和服务。
3.销售应用:当设备使用者在GooglePlay商店中购买应用、游戏或媒体内容时,谷歌会从中提取一定的佣金。
虽然这些途径的收益,也许并不像谷歌的主业——搜索和广告那样让其赚得盆满钵满,但谷歌仍然从中获得了各种“隐性收益”。
因为Android的存在,避免了某一家企业垄断移动平台的入口,只要互联网是开放的,谷歌就能通过吸引更多人使用Android上的应用,来收集用户的行为数据,对这些数据进行加工,从而使得广告投放可以更加精准。
由此可见,开源模式并非与商业化的盈利模式完全冲突,这对于谷歌和开源社区的参与者而言,都是一种好事。
因为只有通过商业化途径,源源不断地为自身“造血”,谷歌和OpenAI等大厂,才能继续承担起训练大参数模型所需的巨额成本。
而只有大参数模型的持续研发,各大开源社区,才能继续以高性能、高质量的预训练语言模型为基础,微调出种类更多,应用场景更为丰富的开源模型。
基于这样的关系,开源模型与封闭的大模型之间,其实不仅仅只是对立与竞争,同时也是一种互助共生的生态。
原文作者:JoséMariaMacedo,DelphiVentures合伙人原文编译:深潮TechFlowCosmos生态向外界展示了强大的增长势头和技术创新.
曹博:上海交通大学凯原法学院副教授、法学博士 要目 一、Web2.0时代视听内容创作传播的数字化二、Web2.0时代视听内容著作权治理范式的制度困境三、Web3.
作者:MilesDeutscher,加密KOL;翻译:金色财经0x25PEPE在短短21天内上涨375,000倍之后,改变了许多人的生活。你也可以通过Meme币改变你的生活.
5月8日,比特币异常拥堵,币安甚至不得不暂停BTC提现交易,这拥堵背后的主要原因是什么?BRC-20代币早在3月时便被提出.
原文作者:0xmin 原文来源:TechFlow深潮 “醋不及防”,PEPE神话又开始让众人开始因别人家的发财故事而感到焦虑.
作者:熊德志 香港虚拟资产交易平台新发牌制度将于6月1日生效,香港证监会将为加密交易所发牌,散户可经持牌平台交易.