背景介绍
我叫小明,是一个每天喜欢胡思乱想的打工人。
随着年轻人的创业热潮的到来,我有一种创业的冲动。经过长时间的探索,我现在萌生出了一个极具创造性的点子,如果以此为依据进行创业的话一定会引起热潮。

首先,为了确定我的想法是不是独一无二的,我必须先通过搜索引擎进行查询。这里有一个我很在意的问题——我在搜索引擎里搜索了我的创意,浏览器会将我的创意直接发送给搜索引擎的服务器,如果我的创意确实是独一无二的,那这样直白的搜索方式一定会把我的创业完全暴露出来,这对我来说非常致命,我绝对不能让任何人有窃取我创意的可能。
如何才能保证在不让搜索引擎知道我具体要查询什么东西的情况下获得我想要的数据是我亟待解决的难题。
简单做法
我的第一个主意是将搜索引擎中所有的数据全部下载下来,将原来的在线查询转换成为本地查询。这就意味着我不用将我的点子发送给服务器端,我就可以充分地保护好自己的隐私了。
不过我还得考虑到另外一个问题,搜索引擎的服务器可是有pb级别的数据量,我下载下来就得花费我几天的时间,另外我还得专门再去买几块大容量的硬盘,这对我来说实在是太过于昂贵。
分?桶
我换了一个想法,既然没机会直接把搜索引擎的数据库都给扒下来,我就试着扒下来一部分数据,然后我再本地查询,这样对我来说,准备的硬盘也可以少一点。
比如说,我本来想要查询的数据是“小明是大帅哥”,这样无疑就向搜索引擎公司暴露我是帅哥的隐私了,那我就可以换一种方式,我就查询“大帅哥”,这样我收到的数据虽然有很多都是我不想要的,但是里面却会包含“小明是大帅哥”的搜索内容。这样,我就将全部的数据库下载换成了部分数据库的下载。获取部分数据库内容以后我就可以本地再去查询了。
这里用到了数据“分桶”的预处理技术,用于减少次要观察误差的影响,是一种将多个连续值分组为较少数量的“桶”的方法。
隐私性保护
分桶的做法虽然很好,但是无疑向数据库泄露了部分隐私,比如“大帅哥”这个信息,虽然服务器没有获知“小明是大帅哥”这个隐私,但是无疑泄露了我对“大帅哥”相关信息比较感兴趣,我不想为了保护我的具体隐私让服务器产生其他的误解。
我只能换一种方式,传统的隐私查询技术给了我一点提示。
▲?背景说明
传统的隐私查询技术对于数据保存结构有特殊的要求:首先数据库得是公开的,即我可以随时调取查看服务器里的任何数据;其次,在很多个服务器上都得部署完全相同的数据库;再者,这些部署了数据库的服务器互相之间不能沟通;最后,假设数据库拥有n个数据X?、X?…?Xn,那么在数据库中其存储形式为一个n维向量。
▲?简单技术方案
如果我现在需要的是数据Xi,那么其实我应该做的事情很简单,就是自己生成一个n维向量,只在第i个位置放1,其余的所有位置都放0,很明显的,这个时候我生成的这个向量和数据库里的向量内积就可以获得结果Xi。
但是这样会存在一个问题,我如果直接将我的向量发送给服务器,他们明显就知道我需要的是什么数据了,那我只能通过另外一种方式来保护我的隐私,将我的向量拆分。如果我把我生成的向量记为r,假设有k个服务器,注意这里k≥2,那么我只用将r拆分成为k个向量即可。更具体的,我可以拆分为:
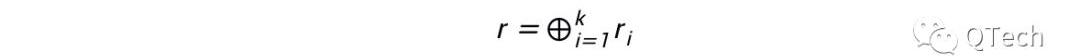
然后将每个分量ri发送给一个服务器。然后服务器自己本地求内积,将结果发送给我,我收到k个结果后求异或就可以复原出Xi的值了。
通过算法描述,相信大家也能理解为什么服务器一定需要大于两个,而且这些服务器之间还不能互相沟通。如果服务器之间互相可以沟通的话就可以复原出我的查询r了。
这个算法有一个很致命的问题,就是我生成的查询r其实是和服务器的数据大小一样大的,如果服务器有几千亿的数据,我的r就得有几千亿维,并没有降低网络消耗,而且更糟糕是,我得生成很多份分量,而每个分量的大小都和数据库一样大,这种方式无疑比直接下载数据更加庞大。
▲?优化技术方案
因为巨大的传输量,我们现在可以对服务器的数据保存方式进行改进,原先的保存方式为向量,现在可以改进为矩阵,假设数据库有25个数据,那么数据将会变成如下形式

我们此时生成的向量就可以从原来的25维缩减到5维,例如我们需要的数据是,在矩阵的第一行,那我们就可以生成查询,此时服务器内积后会将第一行返回给我们。
同之前的方案,我们不能直接将查询r发送给服务器,还是需要进行拆分,然后发送给服务器。同样的流程过后我们就能第一行元素。这样对每个服务器我们上传的数据量为一个5维向量,下载量也同样是一个五维向量,同时,对于每个服务器来说,他们并不知道我们最后拿到的是哪一行。
这个方案的数据总传输量为2k√n,这里的n为服务器拥有的总数据量,k为服务器个数,通常,只需要两个服务器就能达到安全性的要求,故总传输量4√n。
在数据量大于16的情况下,这个策略的数据传输量已经小于直接传输整个数据库的数据量了。
▲?再进阶做法
我按照之前的想法在搜索引擎里查询了一下我的创意,发现里面并没有相关内容。我正准备庆幸没有别人做了和我相同的事情的时候,我的朋友张三麻子和我说我用的搜索引擎查询的结果可能不会很准,推荐了一个相关的收费网站给我,这个网站可以查询到全球所有公司以及其具体业务模式。不过他们是按照查询条数收费的,故不可能像搜索引擎那样随便让我下载资源了。这个时候我的查询数据需要隐私,同时他们的数据库内容也需要隐私。
这个时候可以对之前的算法进行进一步升级,将服务器从2个扩展为4个,我同时发起行查询和列查询。比如我需要的数据,在矩阵里的第一行第三列,那么我就会进行第一行与第三列的查询。行列查询都分别拆分两个分片,这样总共有4种组合可能,四个服务器分别选取其中一种组合本地进行计算。这样服务器便只会发送混淆后的一个元素回来,不会暴露自己的任何额外信息。
讨论及总结
以上的算法有一个很关键的问题,即我知道我需要的数据是数据库中的第几个元素,但是通常情况下,这样的查询方式是不现实的。更为普遍的查询方式为k-v查询,即我依据某个k去数据库查询其对应的v。
例如,我去搜索引擎里搜索“我是大帅哥”,此时k就是“我是大帅哥”,百度返回的搜索结果就是其对应的v。如何将传统的隐私查询技术进行升级以配适现实生活中的实际场景仍需要进一步的探索。
数据安全是现在从个人到国家都非常重视的领域,如何将我们的隐私数据安全的使用起来也是我们一直以来努力的方向。
作者简介
刘毅恒
来自趣链科技数据网格实验室BitXMesh团队,一个鲜为人知的程序员
目前平行链测试网Rococo已经上线公益平行链Statemint,并开始测试资产发行。截止发文,Acala、Zenlink、ChainX、Bifrost已经在Statemint测试网发行了他们自.
南非政府间金融科技工作组近日公布监管沙箱第一批成员,其中包括Ripple合作伙伴MercuryFX。Mercury表示,希望展示其“将汇款缩短至几分钟”的技术能力.
证券日报今日发文称,多家银行均在积极引进数字人民币相关人才。例如,民生及邮储等银行于近期发布的社会招聘启事均涉及数字人民币相关岗位.
据官方消息,DAO-as-a-Service基础设施DoraFactory将于2021年5月1日开启OpenGrantProgram.
4月17日,“超算·融合,2021全球区块链算力大会”在四川成都正式开幕。本届大会由巴比特、链节点、币印联合主办,吴说区块链协办,算力360总冠名.
近期,随着市场热情的持续高涨,NFT开始进入人们的视野,并且持续发酵。据数据统计,NFT全球市值规模已经达到214.79亿美元,成为这轮牛市中最热门的资产类别之一.