在《打破K/V存储的性能瓶颈》中,我们提到区块链中的数据可以分为「连续型数据」和「K/V型数据」,并对K/V型数据的特点及读写进行了阐述。我们以leveldb为例,了解到K/V数据在存储时采用LSM-Tree的组织形式,存储方式相对而言比较复杂,数据读写的复杂度也较高,且在数据量大的情况下会遇到性能下降的问题。针对这些问题,我们已经提出了一些优化思路,但这种数据格式读写的性能存在天然的缺陷。而优化思路里也提到,leveldb的归并操作是为了让SSLTable的key变得有序,说明有序的数据在读写方面有天然优势。
区块链中也有很多数据是有序的。因此,本文将重点讨论连续型数据的特点和连续型数据的读写方式,并根据实际场景中会遇到的问题提出我们的优化思路。
连续型数据,顾名思义,最大的特点就是连续。我们可以把连续型数据当做一种特殊的K/V数据,只不过其key值是单调递增的。
“那么在区块链中,什么样的数据是连续的呢?”
区块链中有一个重要的概念:区块号,就是单调递增的。区块链是一个账本,记下来的账是只增不减的,区块也是不断向后追加的。因此,以区块号为单位存储的数据就可以认为是连续型数据。在上一篇推文中,我们提到除了区块数据以外,回执数据、修改集数据也是连续型数据,这是因为每一条回执,每一条世界状态修改记录,都对应于一笔交易,而交易是区块的组成部分,因此这些数据也可以以区块为单位来存储。

任何数据存储的目的都是为了查询,因此我们在存储连续型数据的同时,需要考虑对这些数据的查询需求。一般来说,对于区块和交易数据,会有以下查询需求:
1)给定一个区块号,查询对应的整个区块数据;
2)给定一个区块哈希,查询对应的整个区块数据;
3)给定一个交易哈希,查询这笔交易的详细信息;
面对这样的查询需求,我们在设计数据库时需要考虑如何支持这些查询。
▲?以太坊
连续型数据作为一种特殊的K/V型数据,自然也可以用K/V数据库来存储,例如以太坊就是这样存的。在以太坊中,所有数据均存储在leveldb中,区块和交易相关的数据存储方式如下:
(H)+BlockHash->BlockNumber
(h)+BlockNumber+(n)->BlockHash
(h)+BlockNumber+BlockHash->BlockHeader
(b)+BlockNumber+BlockHash->BlockBody
(l)+TxHash->BlockNumber
区块数据直接存储在leveldb当中,以区块号和区块哈希为key来进行查询。这样的存储方式很方便,可以根据区块哈希或区块号快速查询到区块内容。但这种方式存储下,leveldb的数据量会很大,数据的读写速度也会受到影响。
▲?HyperledgerFabric
超级账本也是使用键值对数据库存储检索信息,但是额外使用了文件存储系统管理区块数据。通过内存映射文件的方式提高了数据查询的性能,但在多个索引或撤消历史记录的功能上存在局限。对于Fabric的数据存储来说,一般都包含两种方式,如下图所示:
?文件形式存储,用于记录交易日志信息,所有的交易都是有序地连接在一起;
?NoSQL形式存储,使用LevelDB数据库实现保存索引信息的历史记录。
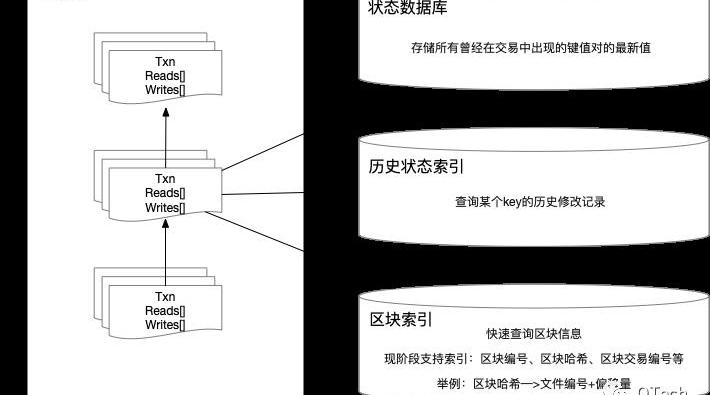
HyperledgerFabric中,账本目录中由blockfile_000000、blockfile_000001命名格式的文件名组成。为了快速检索区块数据,每个文件的大小是64M。每个区块的数据都会序列化成字节码的形式追加写入blockfile文件中。在Fabric中,其索引组织格式如下:
(h)+BlockHash->BlockLoc
(n)+BlockNumber->BlockLoc
(t)+len(TxID)+TxID+BlockNumber+TxNumber->TxIDIndexValue
这里的BlockLoc表示数据在哪个blockfile中以及其偏移量。在Fabric中要根据区块号或区块哈希查询一个区块,将先在leveldb中查询索引,获取BlockLoc之后在文件系统中查询区块。
相比于以太坊而言,Fabric将区块数据存在文件中,大大降低了NoSQL数据库的存储压力,且索引中直接标识数据位置,可以很快在文件中读取到区块数据。
事实上,无论是以太坊还是Fabric,都没有完全利用连续型数据的特点:根据key值来计算偏移量。例如我们知道key为100的数据的位置,就能够推断出,key为200的数据与该位置相差100条数据,这个特点有利于我们快速查找数据。因此,根据偏移量的特点,我们可以进一步减少读写数据的开销。

连续型数据库的整体结构图
数据库由多个logsegment组成,每一个logsegment由一个后缀为.log和一个后缀为.idx的文件组成,分别用于存储数据和对应的索引数据。
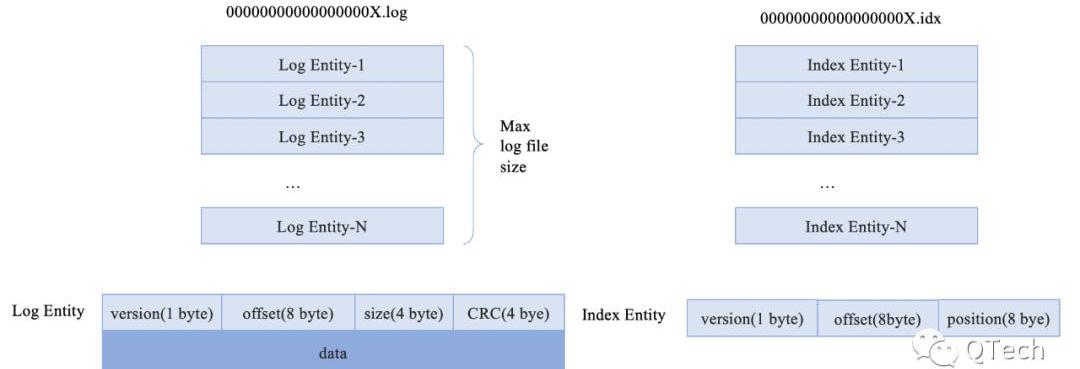
logsegment的结构图
数据以文件的方式记录到磁盘中,log为后缀的文件记录原数据的信息,idx为后缀的文件记录以log文件为单位的文件索引信息,用于快速定位需要查找的数据位置,每一个log文件都配套有一个相同前缀的idx文件。文件名前缀均为文件中存储的第一条数据的偏移量数值。每一个log文件都有大小限制,当文件超过该限制时,新打开一个文件用于后续数据写入。
我们采用logsegment里的第一条数据的key值作为文件名,也是利用到了数据有序这个特点,使用时间复杂度更低的二分查找来快速确认某一条数据位于哪个logsegment中。在这样的数据结构下,数据的读写效率将变得非常高。
对于一次写入操作,就根据数据构造一条LogEntity和一条IndexEntity,直接追加写入到最后一个文件末尾即可。对于一次读取操作,首先根据要读取的数据的key值,使用二分查找找到该数据所在的log文件中,然后根据该key值相对于文件名的偏移量,计算索引所在位置。计算方式如下:
索引位置=偏移量*IndexEntitySize
其中IndexEntitySize的值是一个常量,在我们的设计里大小为17byte,偏移量表示key值相对于文件名的差值。通过计算,可以快速定位到当前key对应数据在文件中位置。通过位置信息,可以读取IndexEntity,得到其中的position字段,找到log文件中的真实读取位置,然后根据log字段中的size得到应该读取的字节范围。
在这样的设计之下,一次数据写入操作只需要两次磁盘IO,一次读取操作只需要三次磁盘IO。相比于LeveDB复杂的数据组织格式,读写效率大大提高。此外,数据量的增大只会增加文件个数,即稍微增加二分查找的时间,但这点计算时间几乎可以忽略不计,也就是说,该数据库随着数据的增大性能不会衰减。
下图为我们设计的连续型数据库相比于LevelDB,可以看出连续型数据库的读写性能远高于LevelDB。
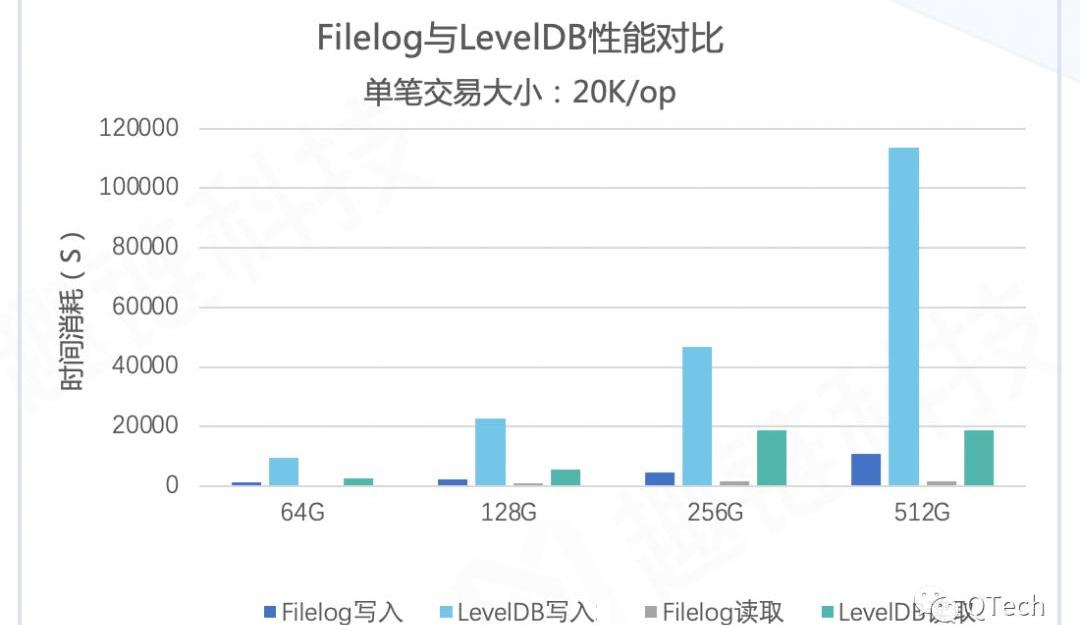
设计这样一个数据库时,初衷是为了能更高效地存储区块数据,让我们的平台拥有更高的性能。随着平台逐渐成熟,我们也不断完善数据库,使其不仅读写效率高,还具有很好的鲁棒性和健壮性,因此我们还从多个角度对我们的数据库进行功能完善和优化,期望能够适应更复杂的存储环境以及更安全地存储数据。
▲?句柄池
在数据库使用过程中,不知道大家会不会经常遇到toomanyopenfiles的问题?那是因为,我们的操作系统对程序中可打开的「句柄数量」是有限制的。为了解决内存中打开的文件句柄过多的问题,更高效地利用句柄,我们引入了一种句柄池的机制来解决上述问题。句柄池的设置能够保证单位时间内句柄的占用内存小,在并发读取下也是线程安全的。
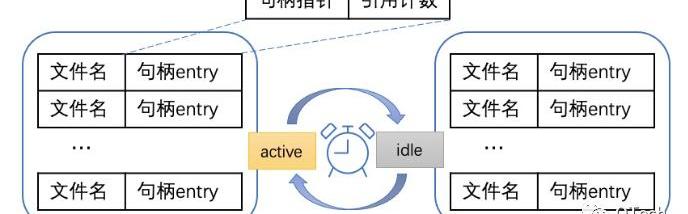
整体架构设计
图中每个句柄entry维护文件名、句柄以及一个引用计数。我们用引用计数表示在当前时间,该句柄在多少个地方正在被使用。只有没有进程在使用该句柄,即句柄引用计数为0的时候句柄才能被关闭。句柄池对外只提供句柄的申请与归还接口。
实际使用过程中,句柄的申请和归还是一个频繁的并发操作,单个句柄池难以同时维护高并发情况下各个句柄的申请与归还。例如刚好要清理句柄时,又出现了该句柄的申请请求,单个句柄池只能通过加读写锁来控制并发,但这势必会降低性能。因此句柄的打开和清理最好分离,所以我们句柄池的设计采用了两个列表轮替的形式,其中一个处于活跃状态,另一个处于清理状态。活跃状态的列表负责维护当前正在使用的句柄,而清理状态的列表则负责将无用句柄关闭。新打开的句柄全部放入活跃列表中,清理列表则负责将所以引用计数为0的句柄关闭。当外部需要获取句柄时,首先在句柄池中查看该句柄是否已经被打开:
如果已经打开,则将其引用计数加1;如果没有打开,则打开句柄,也将引用计数加1,并把句柄放入活跃列表中;外部使用完毕后,归还句柄至句柄池,即句柄的引用计数减1。每隔固定时间,数据库将切换两个列表,原本处于活跃状态的列表将进入后台进行清理,被清理过的列表则转为活跃列表,负责下一阶段里数据库中要使用的句柄的维护。
与此同时,处于清理状态的列表在后台遍历列表,对于引用计数为0的句柄进行关闭。这样的设计能够保证内存不会泄露的同时,更加高效地利用句柄,在频繁读取的情况下保证数据库的性能。
▲?文件完整性
一般来说,成熟的数据库都会保证存入数据的完整性,以防止数据库被篡改或丢失数据却不被发现。在区块链系统中,这一点尤为重要。因此,在上述数据库结构设计的基础上,我们还设计了文件完整性的保证方案。数据库在运行过程中会记录数据状态,当数据库重启时,我们会对数据状态进行校验,以防止数据被篡改。
单条数据的完整性我们已经通过CRC校验码保证了,但单个文件的完整性,我们需要设计其他的机制来保证。我们使用一个EDITLOG文件,用于持久记录存储文件发生的更改。当一个文件写满或者发生变更时,在该文件里追加写入一条记录。记录的格式如下:
文件名变更类型哈希校验码CRC校验码
其中变更类别表示该条记录对应的文件变更操作,由于数据库支持数据归档,因而文件有可能会被新增、删除或切分。
而哈希校验码,我们并没有采用对整个文件内容进行哈希,而是采用对文件名、文件大小和文件修改时间这些信息做哈希计算。因为文件的内容较大,一次哈希的时间会很长,而事实上,防止文件损坏或被篡改,用这几个文件属性就可以基本满足。
CRC校验码则进一步对对文件名和文件变化位计算CRC值,用于保证该条记录不被修改。
本文是存储系列推文的延续,对区块链中连续型数据存储的讲解,着重介绍K/V型数据的存储特点和优化思路,分析了连续型数据的特点,结合以太坊、Fabric存储区块和交易数据的模式,介绍我们设计的连续型数据存储引擎。
通过研究发现,如果利用好连续型数据的特点,其读写效率将远远高于K/V型数据。由此受到启发,在设计或选择数据库的时候,一定要分析我们需要存储的数据特点,根据其特点来设计数据库,才能将性能发挥到极致。
当然,我们在为区块链设计特定的数据库的同时,也希望该数据库能够更加完备与通用,因此也在以一个成熟数据库的标准来优化拓展我们的功能,希望能够应用在更多的场景中。
作者简介
金鹏、王晨璐趣链科技基础平台部区块链存储研究小组
参考文献
https://github.com/ethereum/go-ethereum
https://github.com/hyperledger/fabric
来源:EmpowerLabs 作者:王超 本篇为BanklessDAO系列文章的第三篇,也是最终篇。第一篇对BanklessDAO做了一个简单的全景介绍.
“改变我们传统角色的最大障碍似乎不在于有意识意图的可见世界,而在于潜意识的阴暗领域”。——奥古斯都·纳皮尔博士与奥古斯都博士不同的是,扎克伯格痴迷另外一个“奥古斯都”——征服世界的皇帝——奥古斯.
撰文:MasonNystrom本文编译自MessariWeb3的普及早已在预料之中,但由于需要跨越计算、索引、数据管理、托管、存储和其他重要服务的基础设施,因此需要时间才能完全体现.
10月13日消息,以太坊Layer2网络开发商MatterLabs宣布推出了首个迁移的zksync2.0测试应用UniSync,这标志着zkEVM已实现对Solidity的完全兼容.
原标题:《创造者经济正处于危机之中》本文作者LiJin,AtelierVentures创始人,研究领域创作者经济、DAO、WEB3近两年前,我发表了《激情经济和工作的未来》.
Polkadot生态研究院出品,必属精品波卡一周观察,是我们针对波卡整个生态在上一周所发生的事情的一个梳理,同时也会以白话的形式分享一些我们对这些事件的观察.