
作者|刘大一恒、齐炜祯、晏宇、宫叶云、段楠、周明
编者按:微软亚洲研究院提出新的预训练模型ProphetNet,提出了一种新的自监督学习目标——同时预测多个未来字符,在序列到序列的多个自然语言生成任务都取得了优异性能。
大规模预训练语言模型在自然语言理解和自然语言生成中都取得了突破性成果。这些模型通常使用特殊的自监督学习目标先在大规模无标记语料中进行预训练,然后在下游任务上微调。
传统自回归语言模型通过估计文本语料概率分布被广泛用于文本建模,序列到序列的建模,以及预训练语言模型中。这类模型通常使用teacher-forcing的方法训练,即每一时刻通过给定之前时刻的所有字符以预测下一个时刻的字符。然而,这种方式可能会让模型偏向于依赖最近的字符,而非通过捕捉长依赖的信息去预测下一个字符。有如以下原因:局部的关系,如两元字符的组合,往往比长依赖更强烈;Teacher-forcing每一时刻只考虑对下一个字符的预测,并未显式地让模型学习对其他未来字符的建模和规划。最终可能导致模型对局部字符组合的学习过拟合,而对全局的一致性和长依赖欠拟合。尤其是当模型通过贪心解码的方式生成序列时,序列往往倾向于维持局部的一致性而忽略有意义的全局结构。
THETA跌破9美元关口 日内跌幅为17.54%:欧易OKEx数据显示,THETA短线下跌,跌破9美元关口,现报8.9954美元,日内跌幅达到17.54%,行情波动较大,请做好风险控制。[2021/4/23 20:50:14]
ProphetNet
针对上述问题,我们提出了一个新的seq2seq预训练模型,我们称之为ProphetNet。该模型带有一个新颖的自监督学习目标函数,即预测未来的N元组。与传统seq2seq的Teacher-forcing每一时刻只预测下一个字符不同,ProphetNet每一时刻将学习去同时预测未来的N个字符。如图1所示:
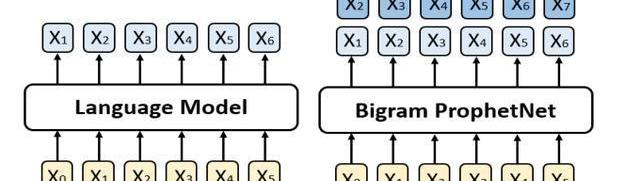
图1:左边是传统的语言模型,每一时刻预测下一时刻的字符。右边是Bigram形式下的ProphetNet,每一时刻同时预测未来的两个字符。
预测未来N元组这一自监督学习目标在训练过程中显式地鼓励模型在预测下一个字符时考虑未来更远的字符,做到对未来字符的规划,以防止模型对强局部相关过拟合。
THETA突破13美元关口 日内涨幅为8.21%:欧易OKEx数据显示,THETA短线上涨,突破13美元关口,现报13.0005美元,日内涨幅达到8.21%,行情波动较大,请做好风险控制。[2021/3/29 19:24:55]
ProphetNet基于Transformer的seq2seq架构,其设计有两个目标:1.模型能够以高效的方式在训练过程中完成每时刻同时预测未来的N个字符;2.模型可以灵活地转换为传统的seq2seq架构,以在推理或微调阶段兼容现有的方法和任务。为此,我们受XLNet中Two-streamselfattention的启发,提出了用于模型decoder端的N-streamself-attention机制。图2展示了bigram形式下的N-streamself-attention样例。
除了原始的multi-headself-attention之外,N-streamself-attention包含了额外的N个predictingstreamself-attention,用于分别预测第n个未来时刻的字符所示。每一个predictingstream与mainstream共享参数,我们可以随时关闭predictingstream以让模型转换回传统seq2seq的模式。
THETA突破5.5美元关口 日内涨幅为6.83%:欧易OKEx数据显示,THETA短线上涨,突破5.5美元关口,现报5.5018美元,日内涨幅达到6.83%,行情波动较大,请做好风险控制。[2021/3/10 18:32:46]
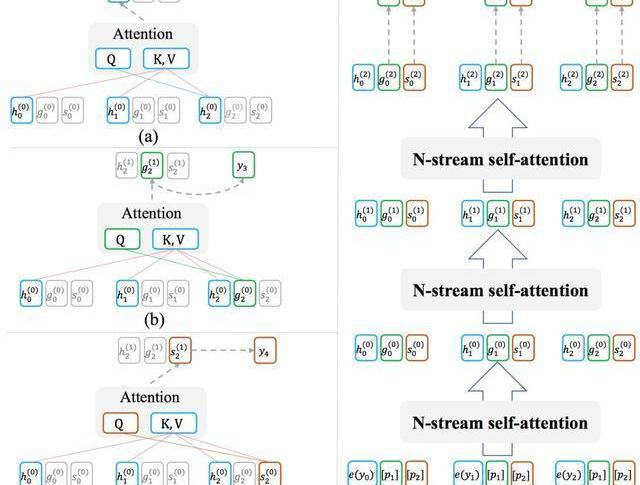
图2:(a)为mainstreamself-attention;(b)为1-stpredictingstreamself-attention;(c)为2-ndpredictingstreamself-attention;(d)展示了n-streamself-attention的输入输出及流程。
由于难以获取到大量带标记的序列对数据,我们用去噪的自编码任务通过大量无标记文本预训练ProphetNet。去噪的自编码任务旨在输入被噪音函数破坏后的序列,让模型学习去复原原始序列。该任务被广泛应于seq2seq模型的预训练中,如MASS、BART、T5等。本文中使用MASS的预训练方式,通过引入提出的predictingn-stream自监督学习目标函数预训练ProphetNet。我们以bigram形式的ProphetNet为例,整个流程如图3所示:
Synthetix已完成Regulus版本升级:合成资产发行平台Synthetix官方发推称,已完成Regulus版本升级。[2020/11/13 14:13:10]
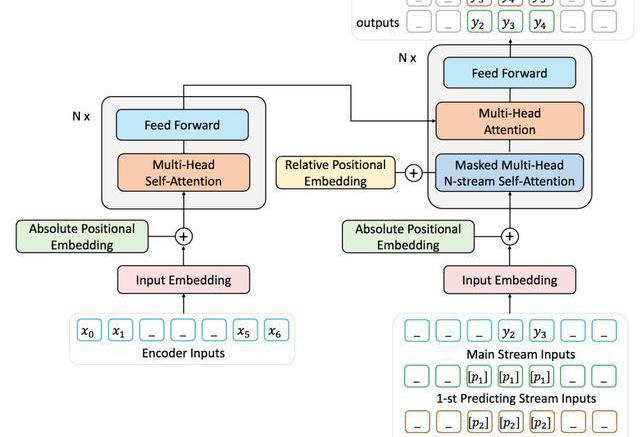
图3:二元形式下的Prophet整体框架图
实验结果
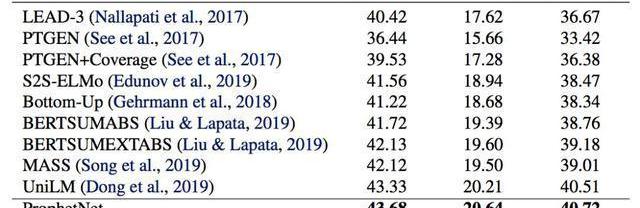
我们使用两个规模的语料数据训练ProphetNet。ProphetNet包含12层的encoder和12层的decoder,隐层大小为1024。先在BERT所使用的BookCorpus+Wikipedia的数据上预训练模型,将模型在Textsummarization和Questiongeneration两个NLG任务上的三个数据集微调并评估模型性能。与使用同等规模数据的预训练模型相比,ProphetNet在CNN/DailyMail、Gigaword和SQuAD1.1questiongeneration数据集上都取得了最高的性能,如表1-3所示。
火币全球站将于5月27日21时暂停THETA充提和TFUEL提币业务:据官方公告,由于THETA主网升级,火币全球站将于5月27日21:00暂停THETA充提业务和TFUEL提币业务。[2020/5/26]
表1:CNN/DailyMail测试集结果
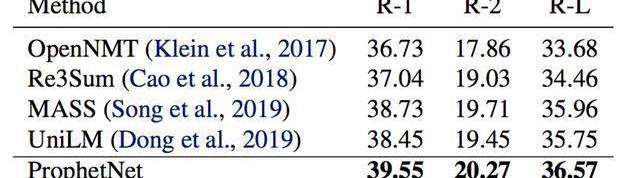
表2:Gigaword测试集结果
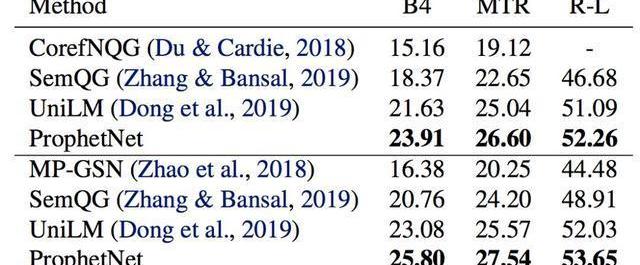
表3:SQuAD1.1测试集结果SQuAD1.1交换验证测试集结果
除了使用16GB的语料训练模型,我们也进行了更大规模的预训练实验。该实验中,我们使用了160GB的语料预训练ProphetNet。我们展示了预训练14个epoch后的ProphetNet在CNN/DailyMail和Gigaword两个任务上微调和测试的结果。如表4所示。需要注意的是,在相同大小的训练数据下,我们模型的预训练epoch仅约为BART的三分之一。我们模型的训练数据使用量仅约为T5和PEGASUSLARGE的五分之一,约为PEGASUSLARGE的二十分之一。尽管如此,我们的模型仍然在CNN/DailyMail上取得了最高的ROUGE-1和ROUGE-LF1scores。并在Gigaword上实现了新的state-of-the-art性能。

表4:模型经大规模语料预训练后在CNN/DailyMail和Gigaword测试集的结果
为了进一步探索ProphetNet的性能,我们在不预训练的情况下比较了ProphetNet和Transformer在CNN/DailyMail上的性能。实验结果如表5所示,ProphetNet在该任务上超越了同等参数量的Transformer。
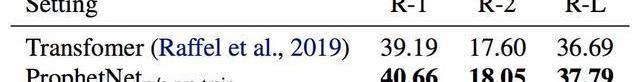
表5:模型不经过预训练在CNN/DailyMail验证集结果
总结
本文介绍了微软亚洲研究院在序列到序列模型预训练的一个工作:ProphetNet,该模型提出了一种新的自监督学习目标,在同一时刻同时预测多个未来字符。并通过提出的N-streamself-attention机制高效地实现了模型在该目标下的训练。实验表明,该模型在序列到序列的多个自然语言生成任务都取得了不错的性能。我们将在之后尝试使用更大规模的模型架构和语料进行预训练,并进一步深入地探索该机制。
论文链接:https://arxiv.org/pdf/2001.04063.pdf
原力计划
《原力计划-学习力挑战》正式开始!即日起至3月21日,千万流量支持原创作者!更有专属等你来挑战
Python数据清理终极指南口罩检测识别率惊人,这个Python项目开源了谈论新型冠状病、比特币、苹果公司……沃伦巴菲特受访中的18个金句,值得一看!天猫超市回应大数据杀熟;华为MateXs被热炒至6万元;Elasticsearch7.6.1发布一张图对比阿里、腾讯复工的区别不看就亏系列!这里有完整的Hadoop集群搭建教程,和最易懂的Hadoop概念!|附代码
标签:HETPROPHETNETPROPInnitForTheTECHprophet币最新消息KIRA NetworkProperSix
意大利古城 中世纪时期意大利社会发展水平曾在西欧位列前茅,孕育出闻名世界的文艺复兴运动,给世界带来了璀璨文化,引起世界各国对意大利的关注。可是,意大利国家长期陷入分裂之中,给它带来了经济影响.
八宝饭财经早讯2020年04月01日星期二八宝饭财经早讯,区块链营养早餐八宝粥已经送达,以太坊2.0第0阶段代码规范最新版本将发布,杜马国加密法已定稿;BTC整体在6400USDT附近调整.
来源:微信公众号“都市快报”因怀疑人民币上可能沾染“新冠肺炎病”,近日江苏无锡江阴市的李阿姨居然把3000多元现金放进微波炉中加热消。还不到一分钟,微波炉就飘出了焦煳味.
编者按许多国家的当地人食用我们认为很奇怪的食物,但中国是世界上食物种类最多的国家之一。在中国的任何一个街市上走走,你都会发现美味佳肴、旅游美食,甚至是彻头彻尾的恶心食物.
比特币最令人困惑的说法是所谓的“去中心化”,这使该货币不受政府控制。所谓“政府不能再利用通货膨胀来剥削人民”,“美联储不能再利用美元来剥削世界”,但问题是,如果没有政府或美联储对人民的剥削,平静.
3月30日是国际医生节,中国红十字基金会字节跳动医务工作者人道救助基金发布受助者图谱,首次对基金资助的医务人员群体进行数据化呈现.