近期ChatGPT爆火,其对传统文字工作的效率提高及总结能力让使用者惊艳。紧随其后CodeGPT这样基于GPT的插件出现,也充分体现了其对代码编写效率的提高。而最新GPT-4的发布,是否可以应用到对区块链、Solidity智能合约的审计中呢?

基于这样的疑问,我们进行了多种可行性测试。
测试环境及测试方法
测试使用的对比模型对象:GPT-3.5(Web),GPT-3.5-turbo-0301,GPT-4(Web)。

代码片段使用Prompt:HelpmediscovervulnerabilitiesinthisSoliditysmartcontract.
漏洞代码片段的检测对比
在此部分,我们分三次测试,使用历史上常见的漏洞代码作为测试一和测试二的用例,来验证其对基础漏洞的检测能力,测试三中使用中等难度的漏洞代码作为测试用例。
测试一
用例:《智能合约安全审计入门篇——Phishingwithtx.origin》
漏洞代码:

对GPT进行提问:

GPT-3.5(Web)answer

GPT-3.5-turbo-0301answer
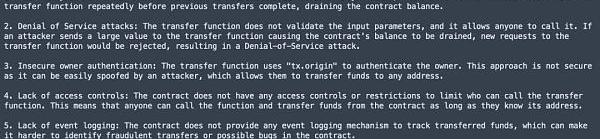
GPT-4(Web)answer

可以看到结果:3个测试版本都发现了关键的tx.origin相关问题。
测试二
用例:《智能合约安全审计入门篇——溢出漏洞》
漏洞代码:

对GPT进行提问:

GPT-3.5(Web)answer

GPT-3.5-turbo-0301answer
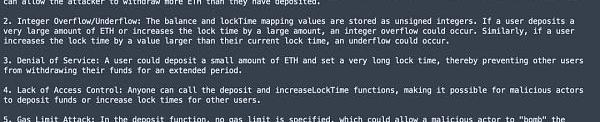
GPT-4(Web)answer


可以看到GPT-3.5(Web)、GPT-3.5-turbo-0301都发现了关键的Overflow漏洞,出乎意料的是GPT-4(Web)居然没有相关提示。
测试三
用例:《空手套白狼——Popsicle被黑分析》
漏洞代码:
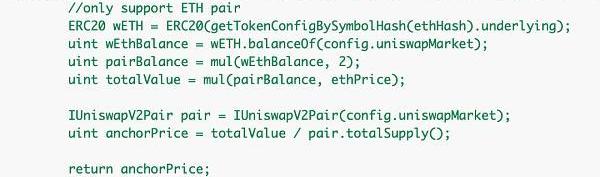
对GPT进行提问:

GPT-3.5(Web)answer

GPT-3.5-turbo-0301answer
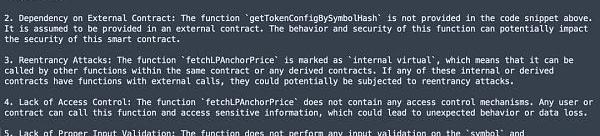
GPT-4(Web)answer

对比结果,我们可以看到3个版本都未发现关键的漏洞点。
代码片段的检测总结
可以看到GPT模型对简单的漏洞代码块的检测能力还是不错的,但是对稍微复杂一点的漏洞代码暂时还无法检测,并且在测试中可以看到GPT-4(Web)的整体上下文可读性很高,输出格式清晰、舒服,但是其对代码的审计能力暂时没有远超GPT-3.5(Web)、GPT-3.5-turbo-0301,甚至在部分测试中由于Transformer输出存在一定的不确定性反而导致GPT-4(Web)遗漏了一些关键问题。
对比已知漏洞的全量合约检测
为了更加契合普通项目方在合约审计中的简单操作需求,这里我们提高些难度,针对代码量大的合约进行全量导入上下文,让GPT-4模型进行审计。
用例:《千万美元被盗——DeFi平台MonoXFinance被黑分析》
整份合约分批输入,在对话最后提出检测漏洞请求
这里使用Prompt:
Hereisasoliditysmartcontract
Contractcode
Theaboveisthecompletecode,helpmediscovervulnerabilitiesinthissmartcontract.

可以看到,GPT-4虽然在OpenAI公布的信息中其单次输入字符总数已经是当前最高,但还是会由于文本超长导致在最后提问时GPT会上下文缺失而只识别到部分内容,所以这样对大型合约而言就无法进行完整的上下文审计。
拆封整份合约,分批输入分批检测
这里使用Prompt:
对话1:
Helpmediscovervulnerabilitiesinthissoliditysmartcontract.
分段内容1
对话2:
Helpmediscovervulnerabilitiesinthissoliditysmartcontract.
分段内容2
对话3:
Helpmediscovervulnerabilitiesinthissoliditysmartcontract.
分段内容3



总结
GPT当前是否适合合约分析
优点
GPT对合约代码中基础的简单的漏洞具备部分检测能力,并且在检测出漏洞后会以很高的可读性来解释漏洞问题,这样的特性比较适合为初级合约审计工作者前期训练提供快速指导和简单答疑。
存在的问题
a.每次生成内容波动
GPT对每次对话的输出存在一定的波动,可以通过API接口参数进行调整,但是依旧不是恒定的输出,虽然这样的波动性对语言对话来说是好的方式,大大提高了对话给人的真实感。但是这对代码分析类的工作来说是一个不好的问题。因为为了覆盖AI可能告知我的多种漏洞回答,我需要多次请求同一问题并进行对比筛选,这无形中又提高了工作量,违背了AI辅助人类提高效率的基准目标。
例如这里再次运行"漏洞代码片段的检测对比测试二:


可以看到其输出结果比之前测试又多了一些额外内容。
b.漏洞分析能力依旧有很大的提高空间
对稍微复杂的漏洞进行检测即会发现当前的训练模型不能正确的分析并找到相关关键漏洞点。
GPT辅助合约审计的可行性和潜力分析
虽然当前来看GPT对合约漏洞的分析及挖掘能力还处于相对较弱的状态,但它对普通漏洞小代码块的分析并生成报告文本的能力依旧让使用者兴奋,在可预见的未来几年伴随这GPT及其他AI模型的训练开发,相信对大型复杂合约的更快速,更智能,更全面的辅助审计一定会实现。当科技发展可指数级提高人工的效率时就会发生质变,我们非常期待AI对区块链安全的助力,我们会持续关注新AI产品对区块链安全的影响。最后可见的将来我们必将与AI在一定程度上进行融合,愿AI和区块链与你同在。
在StarkWare欣欣向荣的StarkNet生态系统,已有105个项目。我们很好奇这些项目都是什么类型的,于是我们做了一些调查。现在,让我们来深入了解下@StarkNet生态系统的项目类型.
永久的溢价 我们如今所见的任何诞生于一千年前的内容都可能经过了编辑,以便更容易理解。说“可能”,是因为没有可以追溯到几个世纪以前的永久的、可核实的工作记录.
区块链和Web3首先是理念创新,其次才是技术创新。在2014到2018年区块链发展的初期,整个行业有很强的理念和愿景引导的气质,当时很多创业者和行业专家都提出了一些非常激动人心的想法.
本周三,BinanceOracle正式上线,自此,世界第一大交易所币安也具备了原生预言机服务。所谓预言机是指将来自外部世界的数据发送到以太坊、BSC等区块链上.
威尔士软件开发者本·阿克(BenArc)在2019年第一次遇到了Nostr的开发者@Fiatjaf,当时他黑入一款吃豆人街机游戏,让它接受比特币.
本文对链游中常见的双币模型和单币模型进行了分析和对比,并在这一过程中探讨了限量代币,无限增发代币和外部货币在游戏中和游戏外的作用,并简述了两类模型的设计思路和优缺点.