来源:AI之势
今年美国科罗拉多州博览会的艺术比赛上,游戏设计师 Jason M. Allen 的作品《太空歌剧院》在数字艺术板块得到一等奖。奖项本身含金量不大,却一石激起千层浪,因为这幅画不是由人动手绘制,而是来自生成式 AI (Generative AI) 产品 Midjourney。
当时艺术正统和机器亵渎引发了争议,其实早在摄影技术兴起时就有过类似的争议,并不妨碍摄影技术革新并,成为了现代艺术的有机组成部分。
因此本文不对此问题做太多探讨,而是旨在对生成式 AI 发展与突破的历史进行复盘,并梳理生成式 AI 会在自然语言、代码、图片、视频、3D 模型等领域带来什么样的下游应用。
回顾历史,人类艺术的发展速度是对数式的,而技术的进步速度是指数式的。生成式 AI 学习了人类艺术对数进化史上的海量画作,实现了创作质量上的指数式进步,并在生产效率上实现了”弯道超车“。模型生成的作品便是今天热议的AIGC (AI Generated Content)。
而本文聚焦的公司 OpenAI ,在这场生成式 AI 的突破中起到了关键性的作用,通过堆叠海量算力的大模型(Foundation Model)使 AIGC 进化。
在 2022 年上半年,OpenAI 旗下三个大模型 GPT-3、GitHub Copilot 和 DALL·E2 的注册人数均突破了 100 万人,其中 GPT-3 花了 2 年,GitHub Copilot 花了半年,而 DALL·E2 只用了2个半月达到了这一里程碑,足见这一领域热度的提升。
研究型企业引领的大模型发展,也给了下游应用领域很大的想象空间,语言生成领域已经在文案生成、新闻撰写、代码生成等领域诞生了多家百万级用户、千万级美金收入的公司。
而最出圈的图片生成领域两大产品 MidJourney 和 Stable Diffusion 都已经有相当大的用户群体,微软也已经布局在设计软件中为视觉设计师提供 AIGC 内容,作为设计灵感和素材的来源。同时 3D 和视频生成领域的大模型也在飞速突破的过程中,未来很可能会在游戏原画、影视特效、文物修复等领域发挥作用。
从神经网络的角度看,当前的大模型 GPT-3 有 1750 亿参数,人类大脑有约 100 万亿神经元,约 100 个神经元会组成一个皮质柱,类似于一个小的黑盒神经网络模块,数量级上的差异决定了算力进步可以发展的空间还很大。与此同时,今天训练 1750 亿参数的 GPT-3 的成本大概在 450 万美元左右,根据成本每年降低约 60% 的水平,供大模型提升计算复杂度的空间还很多。
OpenAI CEO、YC 前主席 Sam Altman 的图景中,AI 大模型发展的最终目标是 AGI(通用人工智能,Artificial General Intelligence),当这一目标实现的时候,人类经济社会将实现”万物的摩尔定律“,即万物的智能成本无限降低,人类的生产力与创造力得到解放。
AI 模型大致可以分为两类:决策式 AI 与生成式 AI。
根据机器学习教科书,决策式模型 (Discriminant Model)学习数据中的条件概率分布;生成式模型 (Generative Model)学习数据中的联合概率分布,两者的区别在于擅长解决问题的方式不同:
决策式 AI 擅长的是基于历史预估当下,有两大类主要的模型应用,一类是辅助决策,常用在推荐系统和风控系统中;第二类是决策智能体,常用于自动驾驶和机器人领域。
生成式 AI 擅长的是归纳后演绎创造,基于历史进行缝合式创作、模仿式创新——成为创作者飞船的大副。所谓 AIGC(AI Generated Content),便是使用生成式AI主导/辅助创作的艺术作品。
不过在10年代的机器学习教科书中,早已就有了这两类AI。为何 AIGC 在20年代初有了显著突破呢?答案是大模型的突破。
时间倒回到 19 年 3 月,强化学习之父 Richard Sutton 发布了名为 The Bitter Lesson(苦涩的教训)的博客,其中提到:”短期内要使AI能力有所进步,研究者应寻求在模型中利用人类先验知识;但之于AI的发展,唯一的关键点是对算力资源的充分利用。“
OpenAI收到日本监管机构关于数据收集的警告:金色财经报道,在日本当地隐私监管机构就其数据收集方法向ChatGPT母公司发出警告后,日本官员开始收紧对人工智能(AI)的立场。6月2日,日本个人信息保护委员会发表声明,要求OpenAI尽量减少为机器学习目的收集的敏感数据量。此外,它强调未经人们许可不得这样做。该委员会还强调需要平衡其隐私问题与留出空间来促进AI的潜在好处,例如推动创新。[2023/6/2 11:55:15]
Seeking an improvement that makes a difference in the shorter term, researchers seek to leverage their human knowledge of the domain, but the only thing that matters in the long run is the leveraging of computation.
该文章在当时被不少 AI 研究者视为对自己工作的否定,极力辩护。但如果拉长时间线回看,会发现这位泰斗所言不虚:
机器学习模型可以从参数量级上分为两类:统计学习模型,如 SVM(支持向量机)、决策树等数学理论完备,算力运用克制的模型;和深度学习模型,以多层神经网络的深度堆叠为结构,来达到高维度暴力逼近似然解的效果,理论上不优雅但能高效的运用算力进行并行计算。
神经网络模型在上世纪 90 年代出现,但在 2010 年前,统计学习模型仍是主流;后来得益于 GPU 算力的高速进步,基于神经网络的深度学习模型逐渐成为主流。
深度学习充分利用了 GPU 擅长并行计算的能力,基于庞大的数据集、复杂的参数结构一次次实现出惊人的效果,刷新预期。大模型便是深度学习模型参数量达到一定量级,只有大型科技公司才能部署的深度学习模型。

2019年,OpenAI 从非营利组织变为营利性公司,接受微软 10 亿美金注资。这一合作奠定了他们有更多算力资源,并能依仗微软的云基础建设随时将大模型(Foundation Model)发布为商用 api。
与此同时,还有第三件事值得关注,大模型 AI 的研究方向出现了转变,从智能决策式 AI 转变为内容生成式 AI:原本主要大模型集中于游戏的智能决策体,如 DeepMind 开发的打败围棋冠军的 AlphaGo、OpenAI 开发的打败 Dota 职业选手的 OpenAI Five。
Transformer 模型(后文将详细介绍)的发布让 OpenAI 嗅到了更适合他们的机会——预训练语言模型。在那之后,他们开始在 AIGC 的方向上开枝散叶:沿着 2018 年时低调发布的 GPT 模型轨迹发布了一系列模型族,一次次刷新文本生成大模型的效果,印证 Sutton 提出的宗旨:充分运用海量算力让模型自由的进行探索和学习。
2019年2月:GPT-2 初版发布,1.2 亿参数量
2019年3月:OpenAI LP 成立
2019年7月:微软注资 10 亿美金
2019年11月:GPT-2 最终版发布,15 亿参数量,宣布暂时不开放使用为避免假信息伪造
2020年6月:GPT-3 发布,1750 亿参数量,后续开放 OpenAI API 作为商用
2021年1月:DALL·E 与 CLIP 发布
2021年10月:OpenAI Codex 发布,为 GPT-3 为 coding 场景的特化模型、Github Copilot 的上游模型
2022年4月:DALL·E2 发布
1、GPT-3,AI文本生成巅峰之作
深度学习兴起于计算机视觉领域的应用,而大模型的发展开始于 NLP 领域。在数据、算力充分发展的过程中,Transformer 模型以 attention 机制高度并行化的结构充分利用算力,成为 NLP 领域预训练模型的标杆。
著名的独角兽 Hugging Face 也是从对该模型的复现和开源起家。除了 attention 机制的高效之外,它还有两个重要特点:迁移学习(transfer learning)和自监督学习(self-supervised learning)。
社交参与平台OpenWeb以1亿美元收购受众管理平台Jeeng以增强社区经济:1月26日消息,据官方消息,社交参与平台 OpenWeb 宣布以 1 亿美元收购受众管理平台 Jeeng 以增强社区经济。据悉,Jeeng 每月为 1.5 亿唯一身份访问者和超过 650 家出版商提供支持,其客户包括 VICE Media、The Atlantic、Crain's、HarperCollins 和 Vox Media 等,Jeeng 首席执行官 Jeff Kupietzky表示,OpenWeb 在创新、安全和已就绪的 Web3 去中心化社交体验方面处于行业领先地位,而 Jeeng 则擅长提供具有内置货币化功能的社区经济。[2023/1/27 11:31:21]
顾名思义,迁移学习指在一个极庞大的数据集上充分学习历史上的各类文本,把经验迁移到其他文本上。
算法工程师会将第一步训练完成的模型存储下来,称为预训练模型。需要执行具体任务时,基于预训练版本,进行定制化微调(fine-tune)、或展示少许范例(few-shot/zero-shot)。
而自监督学习,得从机器学习中的监督学习讲起。前面提到若需要学习一匹马是否在奔跑,需要有一个完整标注好的大数据集。
自监督学习不需要,当 AI 拿到一个语料库,可以通过遮住一句话中的某个单词、遮住某句话的下一句话的方式,来模拟一个标注数据集,帮模型理解每个词的上下文语境,找到长文本之间的关联。该方案大幅提高了对数据集的使用效率。
谷歌发布的 BERT 是 Transformer 时代的先驱,OpenAI 发布的 GPT-2 以相似的结构、更胜一筹的算力后来居上。直到2020年6月,OpenAI 发布了 GPT-3,成为该模型族,甚至整个文本生成领域的标杆。
GPT-3 的成功在于量变产生质变:参数比 GPT-2 多了两个数量级(1750亿vs 15亿个参数),它用的最大数据集在处理前容量达到 45TB。
如此巨大的模型量级,效果也是史无前例的。给 GPT-3 输入新闻标题”联合卫理公会同意这一历史性分裂“和副标题”反对同性恋婚姻的人将创建自己的教派“,生成了一则以假乱真的新闻,评估人员判断出其为AI生成的准确率仅为 12%。以下是这则新闻的节选:
据《华盛顿邮报》报道,经过两天的激烈辩论,联合卫理公会同意了一次历史性的分裂:要么创立新教派,要么”保持神学和社会意义上的保守“。大部分参加五月教会年度会议的代表投票赞成进一步禁止 LGBTQ 神职人员的任命,并制定新的规则”规范“主持同性婚礼的神职人员。但是反对这些措施的人有一个新计划:于2020 年组成一个新教派”基督教卫理公会“。

要达到上述效果,成本不容小觑:从公开数据看,训练一个 BERT 模型租用云算力要花约 1.2 万美元,训练 GPT-2 每小时要花费 256 美元,但 OpenAI 并未公布总计时间成本。考虑到 GPT-3 需要的算力是 BERT 的 2000 多倍,预估发布当时的训练成本肯定是千万美元级别,以至于研究者在论文第九页说:我们发现了一个 bug,但没钱再去重新训练模型,就先这么算了吧。

2、背后DALL·E 2,从文本到图片
GPT-3杀青后,OpenAI 把大模型的思路迁移到了图片多模态(multimodal)生成领域,从文本到图片主要有两步:多模态匹配:将 AI 对文本的理解迁移至对图片的理解;图片生成:生成出最符合要求的高质量图片。
对于多模态学习模块,OpenAI 在 2021 年推出了 CLIP 模型,该模型以人类的方式浏览图像并总结为文本内容,也可以转置为浏览文本并总结为图像内容(DALL·E 2中的使用方式)。
CLIP (Contrastive Language-Image Pre-Training) 最初的核心思想比较简单:在一个图像-文本对数据集上训练一个比对模型,对来自同一样本对的图像和文本产生高相似性得分,而对不匹配的文本和图像产生低相似性分(用当前图像和训练集中的其他对的文本构成不匹配的样本对)。
Dolce&Gabbana、inBetweeners与UNXD在OpenSea上推出新的NFT Drip系列:金色财经报道,Dolce&Gabbana、inBetweeners与UNXD在OpenSea上独家推出新的NFT Drip系列。该系列由GianPiero D'Allesandro设计,包含2,000只数字熊。每只熊都穿着21款独特的 Dolce&Gabbana产品中的一款。更重要的是,持有者将获得与他们的NFT相匹配的独家 Dolce&Gabbana服装和收藏品的实物印刷品。?[2022/12/10 21:35:07]
对于内容生成模块,前面探讨了文本领域:10 年代末 NLP 领域生成模型的发展,是 GPT-3 暴力出奇迹的温床。而计算机视觉 CV 领域 10 年代最重要的生成模型是 2014 年发布的生成对抗网络(GAN),红极一时的 DeepFake 便是基于这个模型。GAN的全称是 Generative Adversarial Networks——生成对抗网络,显然”对抗“是其核心精神。
注:受博弈论启发,GAN 在训练一个子模型A的同时,训练另一个子模型B来判断它的同僚A生成的是真实图像还是伪造图像,两者在一个极小极大的博弈中不断变强。
当A生成足以”“过B的图像时,模型认为它比较好地拟合出了真实图像的数据分布,进而用于生成逼真的图像。当然,GAN方法也存在一个问题,博弈均衡点的不稳定性加上深度学习的黑盒特性使其生成。
不过 OpenAI 大模型生成图片使用的已不是 GAN 了,而是扩散模型。2021年,生成扩散模型(Diffusion Model)在学界开始受到关注,成为图片生成领域新贵。
它在发表之初其实并没有收到太多的关注,主要有两点原因:
其一灵感来自于热力学领域,理解成本稍高;
其二计算成本更高,对于大多高校学术实验室的显卡配置而言,训练时间比 GAN 更长更难接受。
该模型借鉴了热力学中扩散过程的条件概率传递方式,通过主动增加图片中的噪音破坏训练数据,然后模型反复训练找出如何逆转这种噪音过程恢复原始图像,训练完成后。扩散模型就可以应用去噪方法从随机输入中合成新颖的”干净“数据。该方法的生成效果和图片分辨率上都有显著提升。

不过,算力正是大模型研发公司的强项,很快扩散模型就在大公司的调试下成为生成模型新标杆,当前最先进的两个文本生成图像模型——OpenAI 的 DALL·E 2 和 Google 的 Imagen,都基于扩散模型。DALL·E 2 生成的图像分辨率达到了 1024 × 1024 像素。例如下图”生成一幅莫奈风格的日出时坐在田野里的狐狸的图像“:

除了图像生成质量高,DALL·E 2 最引以为傲的是 inpainting 功能:基于文本引导进行图像编辑,在考虑阴影、反射和纹理的同时添加和删除元素,其随机性很适合为画师基于现有画作提供创作的灵感。比如下图中加入一只符合该油画风格的柯基:

DALL·E 2 发布才五个月,尚没有 OpenAI 的商业化api开放,但有 Stable Diffusion、MidJourney 等下游公司进行了复现乃至商业化,将在后文应用部分介绍。
3、OpenAI的使命——开拓通往 AGI 之路
AIGC 大模型取得突破,OpenAI 只开放了api和模型思路供大家借鉴和使用,没去做下游使用场景的商业产品,是为什么呢?因为 OpenAI 的目标从来不是商业产品,而是通用人工智能 AGI。
OpenAI 的创始人 Sam Altman 是 YC 前总裁,投出过 Airbnb、Stripe、Reddit 等明星独角兽(另一位创始人 Elon Musk 在 18 年因为特斯拉与 OpenAI ”利益相关“离开)。
OpenSea协议主管:Seaport不会建立Discord或TG,将在GitHub上启动交流功能:金色财经消息,OpenSea协议主管Kartik发推称,OpenSea不会为Seaport创建一个Discord社群服务器或是Telegram群组,而是选择在GitHub代码库上启动交流功能,如果社区成员对Seaport有任何疑问或想讨论相关开发,可在GitHub进行互动。[2022/6/30 1:40:27]
他在 21 年发布过一篇著名的博客《万物的摩尔定律》,其中提到 OpenAI,乃至整个 AI 行业的使命是通过实现 AGI 来降低所有人经济生活中的智能成本。这里所谓 AGI,指的是能完成平均水准人类各类任务的智能体。
因此,OpenAI 始终保持着学术型企业的姿态处于行业上游,成为学界与业界的桥梁。当学界涌现出最新的 state-of-art 模型,他们能抓住机会通过海量算力和数据集的堆叠扩大模型的规模,达到模型意义上的规模经济。
在此之后克制地开放商业化 api,一方面是为了打平能源成本,更主要是通过数据飞轮效应带来的模型进化收益:积累更富裕的数据优化迭代下一代大模型,在通往 AGI 的路上走得更坚实。

定位相似的另一家公司是 Deepmind——2010年成立,2014 年被谷歌收购。同样背靠科技巨头,也同样从强化学习智能决策领域起家,麾下的 AlphaGo 名声在外,Elon Musk 和 Sam Altman 刚开始组局创办 OpenAI,首要的研究领域就是步 AlphaGo 后尘的游戏决策 AI。
不过 19 年后,两者的研究重心出现了分叉。DeepMind 转向使用 AI 解决基础科学如生物、数学等问题:AlphaFold 在预测蛋白质结构上取得了突破性的进展,另一个 AI 模型 AlphaTensor 自己探索出了一个 50 年悬而未决的数学问题:找到两个矩阵相乘的最快方法,两个研究都登上了 Nature 杂志的封面。而 OpenAI 则转向了日常应用的内容生成 AIGC 领域。
AIGC大模型是通往 AGI 路上极为重要、也有些出乎意料的一站。其重要性体现在 AI 对人类传达信息的载体有了更好的学习,在此基础上各个媒介之间的互通成为可能。
例如从自然语言生成编程语言,可以产生新的人机交互方式;从自然语言生成图片和视频,可以革新内容行业的生产范式。意外性则是,最先可能被替代的不是蓝领,而是创作者,DeepMind 甚至在协助科学家一起探索科研的边界。
OpenAI 的模式也给了下游创业者更多空间。可以类比当年预训练语言模型发展初期,Hugging Face把握机会成为大模型下游的模型开源平台,补足了模型规模膨胀下机器学习民主化的市场空间。
而对 AIGC 模型,未来会有一类基于大模型的创业公司,把预训练完成的 AIGC 模型针对每个子领域进行调优。不只需要模型参数优化,更要基于行业落地场景、产品交互方式、后续服务等,帮助某个行业真正用上大模型。
正如 AI 的 bitter lesson 一样矛盾,投资者需要短期投资回报率、研究者需要短期投稿成功率,尽管OpenAI 走在通往 AGI 正确的路上,这条路道阻且长,短期很难看到极大的突破。而 Sam Altman 展望的大模型应用层公司很有可能有更高的高投资回报,让我们来介绍下主要的分类与创业者。
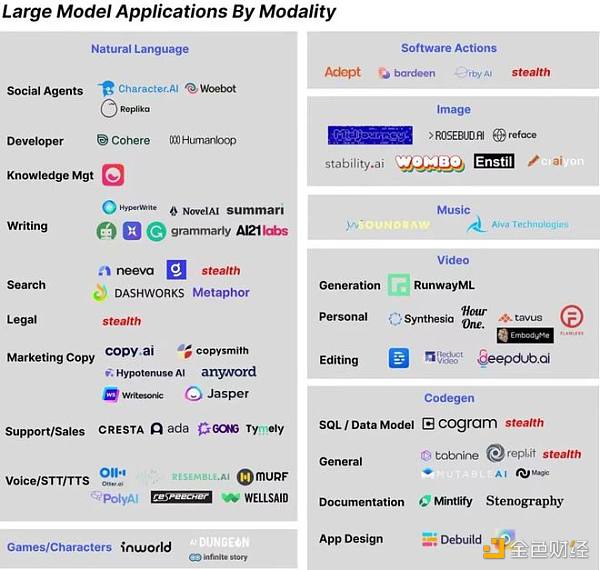
对应 OpenAI 大模型发布的顺序,模型应用层相对最成熟的是文本生成领域,其次是图片生成领域,其他领域由于还未出现统治级的大模型相对落后。
文本领域天然应用场景丰富,且 GPT-3 开放 api 很久,细分赛道很多。大致可以根据生成内容不同分为两类:机器编程语言生成、人类自然语言生成。前者主要有代码和软件行为的生成等,后者主要有新闻撰写、文案创作、聊天机器人等。
而图片领域当前还专注于图片自身内容的生成,预期随着未来3D、视频相关内容生成能力的增强,会有更多结合不同业务场景如游戏、影视这样细分领域的创业公司。
OpenEthereum正式发布v3.1.1版本:1月21日,OpenEthereum官方宣布正式发布OpenEthereum v3.1.1版本。该版本对InvalidStateRoot错误进行了修复。[2021/1/21 16:39:30]
以下是海外各子领域创业公司的梳理,接下来将针对几个领域的重要公司进行介绍。
1、编程语言
文本领域最成熟的应用暂时不在人类自然语言,而是在代码等机器语言的生成领域。因为机器语言相对更结构化,易学习;比如鲜有长文本的上下文关系、基于语境的不同含义等情况。
(1)代码生成:Github Copilot
代表公司是微软出品的 Github Copilot,编程中的副驾驶。该产品基于 OpenAI 专门用 GPT-3 为编程场景定制的AI模型 Codex。使用者文字输入代码逻辑,它能快速理解,根据海量开源代码生成造好的轮子供开发者使用。提高一家科技公司 10% 的 coding 效率能带来很大收益,微软内部已进行推广使用。
相比低代码工具,Copilot 的目标群体是代码工作者。未来的低代码可能是两者结合:低代码 UI 界面实现代码框架搭建,代码子模块通过 Copilot 自动生成。
正如 Copilot 的 slogan:Don’t fly solo,没有 Copilot 的帮助 coder 的工作会变得繁冗,没有 coder 的指引 Copilot 生成的内容可能会出现纰漏。也有用户报告了一些侵犯代码版权、或代码泄露的案例,当前技术进步快于版权法规产生了一定的空白。
(2)软件行为生成:Adept.ai
Adept.ai 是一家明星创业公司。创始团队中有两人是Transformer 模型论文作者,CEO 是谷歌大脑中大模型的技术负责人,已经获得 Greylock 等公司 6500 万美元的 A 轮融资。

他们的主要产品是大模型 ACT-1,让算法理解人类语言并使机器自动执行任务。目前产品形态是个 chrome 插件,用户输入一句话,能实现单击、输入、滚动屏幕行文。在展示 demo中,一位客服让浏览器中自动记录下与某位顾客的电话,正在考虑买 100 个产品。这个任务需要点击 10 次以上,但通过 ACT-1 一句话就能完成。
软件行为生成颠覆的是当下的人机交互形式,使用文字或语音的自然语言形式来代替当下人与机器的图形交互模式(GUI)。大模型成熟后,人们使用搜索引擎、生产力工具的方式都将变得截然不同。
2、自然语言
自然语言下还有多个应用型文本生成领域值得关注:新闻撰写、文案创作、对话机器人等。
(1)新闻撰写
最著名的是 Automated Inights。他们的结构化数据新闻撰写工具叫做 wordsmith,通过输入相应数据和优先级排序,能产出一篇基于数据的新闻报道。该工具已在为美联社每季度自动化产出 300 余篇财报相关报道,在雅虎体育新闻中也已经崭露头角。据分析师评价,由 AI 完成的新闻初稿已接近人类记者在 30 分钟内完成的报道水准。
Narrative Science是另一家新闻撰写生成公司,其创始人甚至曾预测,到 2030 年,90%以上的新闻将由机器人完成。
(2)文案创作
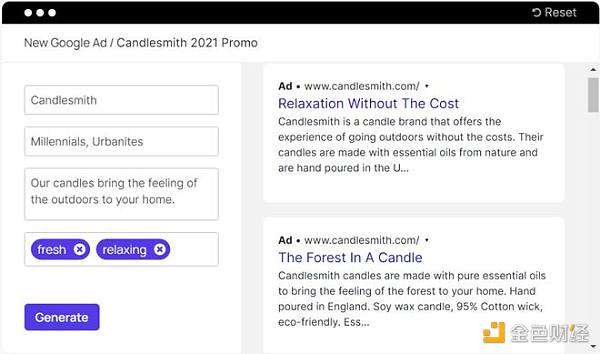
该领域竞争较为激烈,有copy.ai、Jasper、copysmith 等公司。他们基于 GPT-3 的能力加入了文案领域的人工模板与结构,为商家和个人创作者提供了快速为自己的商品、内容进行宣传的能力。以copysmith 为例:
(3)对话机器人
前面提到的 Adept.ai 由Transformer 模型的一作和三作联合创立;而二作也创业了,他创办的 Character.ai 是当前对话机器人中使用效果最逼真的。
该对话机器人可以自定义或使用模板来定义角色的家庭、职业、年龄等,在此基础上保持一贯的设定和符合设定的对话风格。经常能体现出一定的共情对话能力带给人惊喜,并且支持多语言互通。
比如他们有已训练好的马斯克等名人和一些动漫角色,与他们对话会有很棒的代入感。
而商业化的对话机器人,在客服、销售等行业有巨大的市场空间,但如今还为成熟。
主要出现的问题有二:
其一,客服、销售行业遇到的客户往往情绪状态不稳定,AI 难以对情绪进行适应并调整对话内容;
其二,AI 的多轮对话能力较弱,无法保证持续有效的跟进问题。
(4)创作性文本
AI 对于长文本创作有一定困难,难以保持1000字以上的文本创作后仍能进行上下文的联系。
但基于短文本创作仍有一些有趣的应用,例如基于GPT-3的 AI Dungeon,可以引导 AI 创造一个虚拟游戏世界观。该领域进一步的成长需要期待未来 3-5 年,有成熟的能产出千字内容的 AI 出现。
3、多模态图片
DALL·E2 是极具突破性的 AIGC 大模型,但距离丰富生产力和创造力的成熟产品还有差距。因此有研究者顺着 DALL·E 和 CLIP 的思路开发了开源版本的扩散模型,就像当年的 Hugging Face 那样,并将其根据创作者社区的反馈转变为更成熟易用的商业产品。接下来就介绍几个主要出圈的模型:
(1)Disco Diffusion
最早出圈的 AI 绘图工具是开源模型Disco Diffusion。发布时间比 DALL·E 2 稍晚,同样也是 CLIP + Diffusion Model 的结构,生成效果让许多插画师担心起了失业。
尽管很多插画师和 AI 工具爱好者的推荐都认可了该工具的易用性和生成效果的出众,但其生成时间略长有待优化,可以认为是大家对图片生成大模型的初体验。
(2)MidJourney
该模型发布后不久,Disco Diffusion 的开发者 Somnai 加入了 MidJourney,和团队一起打造了一款产品化的 Disco Diffusion。
Midjourney 的创始人 David Holz 并不是以CV(计算机视觉)研究为主,更关注人机交互。产品公测和主要交流平台都基于Discord,使用 Discord Bot 进行交互,打造了相当良好的社区讨论环境。
使用中印象深刻的有几个重要功能:MidJourney 画廊中可以看到每时每刻创作者们用 MJ 创作出的作品,用户可以对作品进行打分,每周排名靠前的作品将得到额外的 fast GPU 时间奖励。
同时,MJ官方还为用户贴心的提供了引导语 prompt 集合和 AI 擅长的风格指南,指导用户如何最高效的生成出他们想要的图片。
基于良好的产品和社区体验,MidJourney 的付费用户量也是目前最大的。
目前收费模式采用了订阅制,个人用户有两个档位,每月最多 200 张图片(超额另收费)的 10 美元/月,以及”不限量“图片的 30 美元/月;对企业客户,单人一年收费仅有 600 美元,且生成的作品可以商用(当前法规尚不完善,仍可能存在一定版权问题)。
(3)Stable Diffusion
如果说 MidJourney 是一个勤勤恳恳的绩优生,那么 Stability.ai 则是天赋异禀技术力强、诞生之初就备受 VC 追捧的富二代,公司估值已达到十亿美元。产品 Stable Diffusion 首要目标是一个开源共创模型,与当年的 Hugging Face 神似。
创始人 Emad 之前是对冲基金经理,用自己充裕的资金联合 LMU 和 Runaway ML开发了开源的 Stable Diffusion,在 Twitter 上使用扎克伯格在 Oculus 发布会上的照片作为背景,号召SD会成为”人类图像知识的基础设施“,通过开源让所有人都能够使用和改进它,并让所有人更好地合作。
Stable Diffusion 可以认为是一个开源版本的DALL·E2,甚至不少使用者认为是当前生成模型可以使用的最佳选择。官方版本部署在官网 Dream Studio 上,开放给所有用户注册。
相比其他模型,有很多可以定制化的点。不过官网只有 200 张免费额度,超过需要付费使用,也可以自行使用开源 Colab 代码版无限次使用。此外,Stable Diffusion 在压缩模型容量,希望使该模型成为唯一能在本地而非云端部署使用的 AIGC 大模型。
05 AIGC大模型的未来展望 1、应用层:多模态内容生成更加智能,深入各行业应用场景
上述的多模态图片生成产品当前主要局限于创作画作的草图和提供灵感。在未来待版权问题完备后, AIGC 内容能进入商用后,必然会更深入地与业界的实际应用进行结合:
以游戏行业为例, AI 作画给了非美术专业工作者,如游戏策划快速通过视觉图像表达自己需求和想法的机会;而对美术画师来说,它能够在前期协助更高效、直接地尝试灵感方案草图,在后期节省画面细节补全等人力。
此外,在影视动画行业、视频特效领域,甚至是文物修复专业,AI 图片生成的能力都有很大想象空间。当然,这个领域 AI 的能力也有着不小的进步空间,在下面的未来展望部分进行阐发。
目前 AIGC 存在 Prompt Engineering 的现象,即输入某一些魔法词后生成效果更好。这是目前大模型对文本理解的一些缺陷,被用户通过反向工程进行优化的结果。未来随着语言模型和多模态匹配的不断优化,不会是常态,但中短期内预期Prompt Engineering 还是得到好的生成内容的必备流程之一。
2、模态层:3D生成、视频生成 AIGC 未来3-5年内有明显进步
多模态(multimodal)指不同信息媒介之间的转换。
当前 AI 作图过程中暴露的问题会成为视频生成模型的阿喀琉斯之踵。
例如:AI 作画的空间感和物理规则往往是缺失的,镜面反射、透视这类视觉规则时常有所扭曲;AI 对同一实体的刻画缺少连续性。根本原因可能是目前深度学习还难以基于样本实现一些客观规则泛化,需要等待模型结构的优化进行更新。
3D生成领域也有很大价值:3D 图纸草图、影视行业模拟运镜、体育赛场现场还原,都是 3D 内容生成的用武之地。这一技术突破也渐渐成为可能。
2020年,神经辐射场(NeRF)模型发布,可以很好的完成三维重建任务:一个场景下的不同视角图像提供给模型作为输入,然后优化 NeRF 以恢复该特定场景的几何形状。
基于该技术,谷歌在2022年发布了 Dream Fusion 模型,能根据一段话生成 360 度三维图片。这一领域当前的实现效果还有优化空间,预期在未来3-5年内会取得突破性进展,推动视频生成的进步。
3、模型层:大模型参数规模将逼近人脑神经元数量
近年的大模型并未对技术框架做颠覆性创新,文本和图像生成领域在大模型出现前,已有较成熟方案。但大模型以量变产生质变。
从神经网络角度看,大脑有约 100 万亿神经元, GPT-3 有 1750 亿参数,还相差了 1000 倍的数量级,随着算力进步可以发展的空间还很大。
神经网络本质是对高维数据进行复杂的非线性组合,从而逼近所观测数据分布的最优解,未来一定会有更强的算力、更精妙的参数堆叠结构,来刷新人们对AI生成能力的认知。

4、成本结构决定大模型市场的马太效应
大模型最直接的成本便是能源成本(energy cost),GPT-3 发布时的训练成本在千万美元级别。难以在短期内衡量 ROI ,大科技公司才能训练大模型。
但随着近年模型压缩、硬件应用的进步,GPT-3 量级的模型成本很可能已降至百万美元量级,Stable Diffusion 作为一个刚发布一个月的产品,已经把原本 7GB 的预训练模型优化压缩至 2GB 左右。
在这样的背景下,算力成本在未来必然会逐渐变得更合理,但 AIGC 领域的另一个成本项让笔者对市场结构的预测还是寡头垄断式的。
大模型有明显的先发优势,来自巨大的隐形成本:智能成本。前期快速积累用户反馈数据能帮助模型持续追新优化,甩开后发的竞争者,达到模型性能的规模效应。
AI 的进化来自于数据的积累和充分吸收。深度学习,乃至当前的所有机器学习都是基于历史预估未来,基于已有的数据给到最接近真实的可能。
正如前文讨论的,OpenAI 的目标从来不是留恋于某个局部行业的商业产品,而是通过模型规模经济,不断地降低人类社会全局的智能成本,逼近通用人工智能 AGI。规模经济正体现在智能成本上。
5、虚拟世界的 AGI 会先于现实世界诞生
从更宏观的视角上,虚拟世界 AI 技术的智能成本比现实世界中来得低得多。现实里 AI 应用最普遍的是无人驾驶、机器人等场景,都对 Corner Case 要求极高。
对于AI模型而言,一件事超过他们的经验范畴(统计上out of distribution),模型将立马化身人工智障,不具备推演能力。现实世界中 corner case 带来的生命威胁、商业资损,造成数据积累过程中极大的试错成本。
虚拟世界则不同,绘图时遇到错位扭曲的图片,大家会在 Discord 中交流一笑了之;游戏 AI 产生奇怪行为,还可能被玩家开发出搞怪玩法、造成病传播。
因此虚拟世界,尤其是泛娱乐场景下的 AIGC 积累数据成本低会成为优势。这个领域的 AI 如果节省人力、生成内容产生的商业价值能大于算力成本,能很顺畅地形成低成本的正向循环。
伴随着另一个重要的革新——长期 Web3.0元宇宙场景下新内容经济生态的形成,虚拟世界内容场景下的 AI 很可能更早触及到 AGI。
金色早8点
金色财经
Odaily星球日报
欧科云链
Arcane Labs
深潮TechFlow
MarsBit
澎湃新闻
BTCStudy
链得得
摩根大通认为,1月CPI同比增长6.0%到6.3%的几率为65%,若这样增长,标普500会涨1.5%到2%,然后涨势消退;CPI同比增长6.4%到6.5%的几率为25%,若这样增长.
作者 :特约研究员 William 吴说授权发布 2023 年 2 月 20 日.
社交媒体已经改变了我们的沟通方式,但不是每个人都认为这些变化总是积极的。许多社交媒体平台都因没有适当调整内容而受到批评,导致虚假信息的传播.
原文作者:yyy 昨晚 Coinbase 宣布入场做了一条基于 OP Stack 的 L2——@BuildOnBase, 一时间「Bullish on Optimism」的情绪又再度被点燃.
作者:吴文谦 吴文谦,现为 TKX 资本的合规合伙人,香港特别行政区高等法院执业律师。他曾领导火币和 OKX 加密交易所法律和合规职能,并为累计筹集超过 2 亿美元的加密项目和加密基金提供咨询.
让玩家进入传统游戏的过程通常很简单。在 Web2,玩家可以方便地使用他们现有的社交帐户,例如 Apple ID 或 Google 来登录游戏.