撰文:Tanya Malhotra
来源:Marktechpost
编译:DeFi 之道

图片来源:由无界版图AI工具生成
随着生成性人工智能在过去几个月的巨大成功,大型语言模型(LLM)正在不断改进。这些模型正在为一些值得注意的经济和社会转型做出贡献。OpenAI 开发的 ChatGPT 是一个自然语言处理模型,允许用户生成有意义的文本。不仅如此,它还可以回答问题,总结长段落,编写代码和电子邮件等。其他语言模型,如 Pathways 语言模型(PaLM)、Chinchilla 等,在模仿人类方面也有很好的表现。
?OpenAI:将在未来几个月推出ChatGPT企业版订阅服务:金色财经报道,OpenAI表示,正在研究推出新企业版ChatGPT订阅服务,主要针对那些希望更多掌控数据的专业人士以及寻求管理终端用户的企业。“我们计划在未来几个月内推出企业版”,该公司还表示,已经引入关闭ChatGPT聊天记录的功能。(鞭牛士)[2023/4/30 14:35:09]
大型语言模型使用强化学习(reinforcement learning,RL)来进行微调。强化学习是一种基于奖励系统的反馈驱动的机器学习方法。代理(agent)通过完成某些任务并观察这些行动的结果来学习在一个环境中的表现。代理在很好地完成一个任务后会得到积极的反馈,而完成地不好则会有相应的惩罚。像 ChatGPT 这样的 LLM 表现出的卓越性能都要归功于强化学习。
Flippening Otters NFT集成多种Chainlink服务,以可靠地铸造NFT:10月31日消息,Flippening Otters项目已正式在Ethereum上集成Chainlink VRF (可验证随机函数),并计划集成Chainlink Keepers。Flippening Otters是一个关于Ethereum历史的NFT合集,由9,999个发布时独特生成的Otter NFT和最后1个 “Great Flippening Otter” NFT组成。“Great Flippening Otter” 会在达到 “Flippening” 期时随机奖励给一个持有Flippening Otter的地址。[2021/10/31 21:13:00]
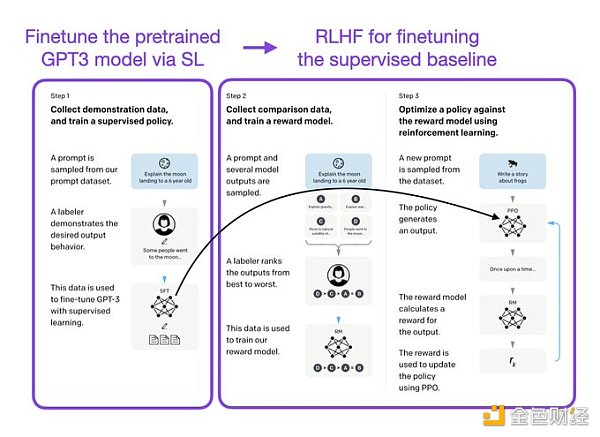
ChatGPT 使用来自人类反馈的强化学习(RLHF),通过最小化偏差对模型进行微调。但为什么不是监督学习(Supervised learning,SL)呢?一个基本的强化学习范式由用于训练模型的标签组成。但是为什么这些标签不能直接用于监督学习方法呢?人工智能和机器学习研究员 Sebastian Raschka 在他的推特上分享了一些原因,即为什么强化学习被用于微调而不是监督学习。
动态 | 加密货币钱包提供商Blockchain投诉山寨网站:据CCN消息,加密货币网络钱包提供商Blockchain已在美国联邦法院提起诉讼,指控山寨网站blockchain.io试图用户。根据Blockchain的说法,这个假设的新机构实际上是一个原始名称为Paymium的旧平台,也被称为“Instawallet”,曾在2013年一次广为人知的黑客攻击中损失了用户资金。[2018/9/23]
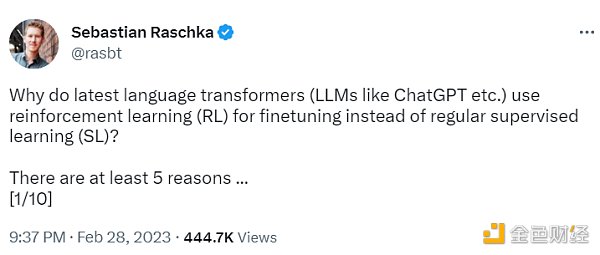
不使用监督学习的第一个原因是,它只预测等级,不会产生连贯的反应;该模型只是学习给与训练集相似的反应打上高分,即使它们是不连贯的。另一方面,RLHF 则被训练来估计产生反应的质量,而不仅仅是排名分数。
TopChain 创始人焦光明:区块链开启游戏新模式:据金色财经前方记者报道,TopChain 创始人焦光明在“2018 TOKENSKY区块链大会”表示,区块链技术可以和游戏非常好地结合,区块链可以开启一种新的游戏模式。现存的游戏开发和推广过程存在诸多问题,TopChain希望通过去中心化的技术,转变玩家角色,使其不仅可以玩游戏,还可以通过游戏赚钱,甚至参与决策。[2018/3/14]
Sebastian Raschka 分享了使用监督学习将任务重新表述为一个受限的优化问题的想法。损失函数结合了输出文本损失和奖励分数项。这将使生成的响应和排名的质量更高。但这种方法只有在目标正确产生问题-答案对时才能成功。但是累积奖励对于实现用户和 ChatGPT 之间的连贯对话也是必要的,而监督学习无法提供这种奖励。
不选择 SL 的第三个原因是,它使用交叉熵来优化标记级的损失。虽然在文本段落的标记水平上,改变反应中的个别单词可能对整体损失只有很小的影响,但如果一个单词被否定,产生连贯性对话的复杂任务可能会完全改变上下文。因此,仅仅依靠 SL 是不够的,RLHF 对于考虑整个对话的背景和连贯性是必要的。
监督学习可以用来训练一个模型,但根据经验发现 RLHF 往往表现得更好。2022 年的一篇论文《从人类反馈中学习总结》显示,RLHF 比 SL 表现得更好。原因是 RLHF 考虑了连贯性对话的累积奖励,而 SL 由于其文本段落级的损失函数而未能很好做到这一点。
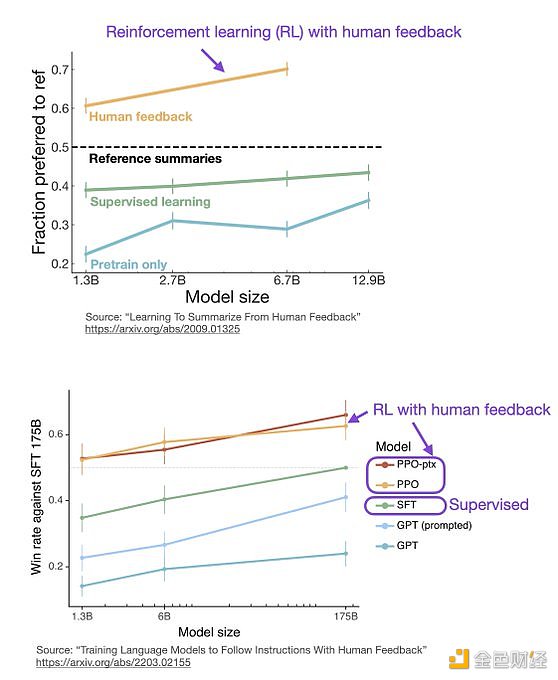
像 InstructGPT 和 ChatGPT 这样的 LLMs 同时使用监督学习和强化学习。这两者的结合对于实现最佳性能至关重要。在这些模型中,首先使用 SL 对模型进行微调,然后使用 RL 进一步更新。SL 阶段允许模型学习任务的基本结构和内容,而 RLHF 阶段则完善模型的反应以提高准确性。
DeFi之道
个人专栏
阅读更多
金色财经 善欧巴
金色早8点
Odaily星球日报
欧科云链
Arcane Labs
MarsBit
深潮TechFlow
BTCStudy
澎湃新闻
ChatGPT爆火之后,各种「自制API」层出不穷,中间商们也一个个赚得盆满钵满。 这次,OpenAI终于下定决心——正式开放ChatGPT API! ChatGPT API地址:https://platform.openai.com/docs/guides/chat 现在,不要耗费数年,不要投资数十亿美元,企业、个人开发者就能使用ChatGPT这样的。
编辑:Bowen@Web3CN.Pro3月9日消息,无聊猿Bored Ape Yacht Club母公司Yuga Labs公布了其Otherside元宇宙游戏平台第二次测试的最新细节.
原文作者:Arthur Hayes 原文编译:GaryMa 吴说区块链 自从美联储在 2022 年 3 月开始加息以来,我一直认为,最终的结果总是会出现重大的金融动荡,接着就是恢复印钞。
作者:Chloe 目前以太坊基于零知识证明的扩容方案是ZK-rollup,但其实还有另外两种解决方案——Validium和Volitions。本文简单介绍以上3种基于零知识证明的扩容方案.
图片来源:由无界版图AI工具生成3月2日,OpenAI正式开放了ChatGPT的API接口,开发人员可以将ChatGPT模型集成到他们的应用程序和产品中.
撰文:Mary Liu 加密社区最期待的大事之一 --Arbitrum 空投 -- 终于来了。Arbitrum Foundation 宣布将于 3 月 23 日向其社区成员空投 ARB 治理代币.