人工神经网络
一个最重要的创新:人工神经网络

简单来讲,神经网络意味着理论上它可以学习任何用户动作的映射!
为了介绍一会儿将使用的一些术语,从状态到行动的映射将被称为“策略”。
为了让拳手的神经网络学习策略,AI Arena将采取模拟学习和强化学习。其中神经网络架构存储在IPFS上。
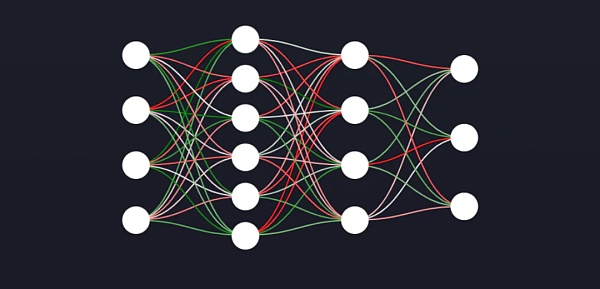
在上图中,神经元之间的连接称为“权值”。当你的神经网络正在“学习”时,所发生的是它正在改变权值的值。
权值最终将决定状态如何映射到动作,这意味着我们可以将权值解释为“智能”。
神经网络权值对于每个NFT都是唯一的,并存储在以太坊上。
AI设计机制全攻略
状态
Web3游戏开发公司Cinder Studios完成A轮融资,Animoca Brands领投:5月25日消息,Web3游戏开发公司Cinder Studios宣布完成A轮融资,本轮融资由Animoca Brands领投,具体融资金额暂未披露,本轮融资资金将用于加速产品研发,包括开发P2E类游戏、铸造新头像并推出自己的专属Token。
此外,Cinder Studios还将进一步加速构建其基于Solana区块链的MMO游戏并发行NFT,Cinder NFT持有者除了可以在虚拟世界中进行社交外,还能使用强大的创建者工具打造游戏内角色以及其他内容。(wildfire.news)[2022/5/25 3:41:33]
(1)什么是状态?
状态是环境在某个时间点的表示。它并没有包含所有信息——只包含了其中必要的信息。
例如:研究人员使用屏幕上的所有像素作为状态,让AI计算出像素代表什么。然后根据他们认为对决策过程重要的因素进行人工调试。
AI Arena一再强调其关心的是为所有人提供平等的机会——团队希望奖励能够更多地给予坚持训练AI的用户,而不是奖励拥有更多资源的用户。
传科技巨头Meta已暂停自研处理器开发:4月22日消息,据外媒报道,Meta(原Facebook)公司日前决定暂缓为其AR眼镜产品自研处理器的努力,转而决定继续使用高通芯片。此前Meta据传有意为其AR/VR产品开发专用处理器,以摆脱对高通产品的依赖,并实现更好的定制性能。 (金十)[2022/4/22 14:41:08]
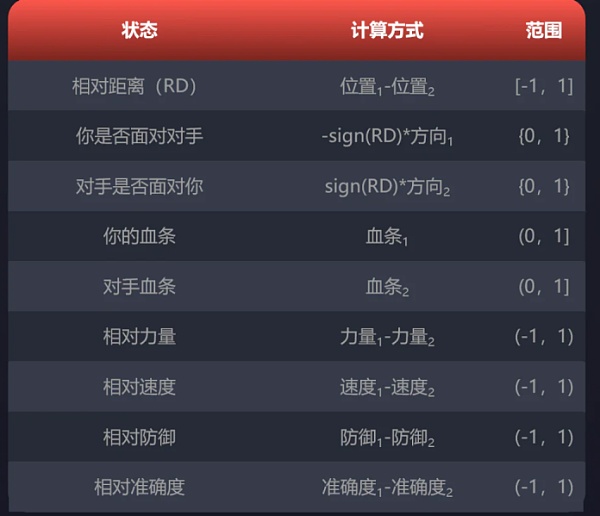
(2)游戏将使用哪些变量?
下面是状态中包含的变量列表。需要注意的是,AI Arena将使用下标1表示用户自己的AI,下标2表示对手。
此外,竞技场的左边界的X位置为0,右边界的X位置为1。
训练
(1)训练概述
这是改变神经网络中权值的过程,以使AI能够起作用。
例如:如果我们在对手面前,我们可能希望我们的战士出击。
有一系列的权值可以实现这一点,训练的重点是让AI学会在特定场景中采取特定的行动。
A股开盘:深证区块链50指数上涨0.13%:金色财经消息,A股开盘,上证指数报3371.26点,开盘上涨0.12%,深证成指报13791.41点,开盘上涨0.2%,深证区块链50指数报3780.84点,开盘上涨0.13%。区块链板块开盘下跌0.1%,数字货币板块开盘上涨0.03%。[2020/12/16 15:19:59]
AI Arena在应用程序中嵌入了以下培训计划:
模仿学习
为了学习如何战斗,你的AI将观察你并学习模仿你的动作。
自我学习
为了学习你无法教给它的技能,你的AI将与自己的副本对抗,以不断提高。

(2)为什么需要训练?
1·随机初始化
首次创建NFT拳手时,神经网络权值也随之生成。一开始它会随机采取行动,因为它不知道在什么情况下应该采取什么行动。
因此为了准备战斗,我们必须训练它,使它学会一个好的作战策略。
2·随机策略
正如上文“神经网络”部分中提到的,从状态到动作的映射称为策略。
换句话说,策略定义了代理在某些情况下的行为方式。在训练之前,NFT拳手还没有学会一个好的战斗策略,所以只是随机行动。
(1)通过观察学习
理解模仿学习的最好方法是想象你是一个师父,你的AI是一个你正在准备战斗的战士。
你用你的人工智能进行搏击,它学习模仿你在特定场景中的动作。
我们正在写一篇关于模仿学习的综合博文,到时候会将其链接到这里。
(2)演示
实际情况:你实际操控的是左边的灰色拳手,而你的AI在右边。你可以测试一些动作,观察AI如何模仿你。
请注意:它不会立即复刻你的动作,因为神经网络需要一点时间来学习,所以在AI学会之前,你可能需要多重复几次你的动作。
为简单演示,目前AI Arena只允许用户使用这些操作:向左跑、向右跑、单拳、双拳和防守。

(1)完美匹配
最完美的拳击搭档就是用户自己。通过自我学习,你的AI总是在不断地挑战自己,不断地改进。
(2)不同的学习范式
通过模仿学习,AI通过观看演示进行学习。在自我学习中,AI像对手一样学习和战斗没有多大意义,因为对手是人工智能本身的克隆。
但是如果没有专家向人AI展示如何战斗,那么它如何学习该做什么呢?——通过奖励。
AI将学会采取给予它更多正向奖励的行动,而减少采取给予它负面奖励的行动。
定制训练
Python环境[正在准备中]
AI Arena计划为玩家引入一个python环境来训练他们自己的模型。
目前,用户仅限于使用团队在应用程序中提供的两种培训方法;但不久的将来,应用程序将可以允许玩家导入其自定义培训模型并上链。
游戏模式探索

战斗
AI Arena目前有两种可用的作战模式:模拟赛和排位赛。除此之外,团队计划在不久后整合另外两种作战模式。
1)模拟赛
玩家可以在对抗竞技场测试他们的拳手来预先训练的AI。在这种模式下将没有任何奖励。
2)排位赛
玩家将让他们的拳手去对抗来自世界各地的拳手。玩家的唯一目标就是努力攀登排行榜,成为竞技场的冠军!
玩家在排行榜上的排名越高,赢得一场战斗的回报奖励就越高。
3)目标
虽然每种战斗模式都有其独特之处,但它们都有一个共同的胜利目标:在指定的时间内消耗对手所有生命值。
链金交易员总结
目前AI Arena尚处在早期,很适合提前埋伏观察。据官方透露,游戏正式版本大概率于明年推出,而今年年末推出的测试版本将只有白名单用户可以参与体验。
白名单用户名额的获取方式是参与团队即将推出的解密游戏,通过游戏后的用户将会被随机选择是否进入白名单。
有兴趣的玩家可以加入他们的Discord尝试体验,大概率后期会有早鸟空投奖励。
经过一年多的厚积薄发,高性能公链Fantom的生态迎来了总爆发,FTM的价格与两个月前相比上涨了一倍,各种熟悉的交易所、挖矿项目又在Fantom重新上演。 岁末时分,看紧钱袋子是老祖宗留下来的智慧。所谓早发现、稳布局、快盈利,是当前加密市场环境下胜率最大的原则。
自Facebook母公司更改名为「Meta」、布局元宇宙之后,互联网巨头和资本纷纷跟进。11月初,英伟达宣布布局虚拟身份;微软则表示将植入虚拟体验协作平台并引入宇宙元素;软银领投区块链元宇宙元素的游戏The Sand box,该游戏获得了9800万美元融资。
我们目前还没有触及 DeFi、DAO 和现实世界生活的可能性。 现在 Web3 中的兴奋情绪和财富创造意味着 DAO 可以为传统上难以筹集资金的项目筹集大量资金。CabinDAO 就是一个很好的例子。 DeFi 中异常高的收益率意味着 DAO 可以将他们的资金用于改善其成员的生活,这比陷入传统金融的正常业务更有效。
本文提及数据网站: https://dappradar.com/rankings https://cryptoslam.io https://playtoearn.net/blockchaingames https://nonfungible.com https://www.blockchaingamealliance.org https://www。
市场上有几种去中心化杠杆代币模型,包括Set Protocol、Tracer和Phoenix Finance。它们都对杠杆头寸的代币化应用了非常不同的方法。 杠杆代币是一种衍生品,为持有者提供了对加密资产的稳定杠杆敞口。代币持有者不需要担心主动管理杠杆头寸、借款或清算。 固定的杠杆或杠杆范围由再平衡机制维持。
Splinterlands是NFT世界中的P2E游戏的创新补充。该游戏以前称为Steem Monsters,在Hive区块链上运行,属于交易游戏类型。 与市场上的大多数NFT游戏不同,Splinterlands提供与其他区块链(包括Tron、以太坊和WAX)的交叉兼容功能。