▲联邦学习问题回顾前文提及,于2016年,Google提出了用于训练输入法模型的新型方式,称为「联邦学习」。随着时间的推移,联邦学习不再是单纯解决Google输入法模型的一种解决方案,进而形成了一种新型的学习模式。联邦学习解决的问题通常被称为TMMPP--TrainingMachineLearningModelsovermultipledatasourceswithPrivacy,即在保证多方参与者的数据不泄露的情况下,共同完成预定模型的训练。在联邦学习解决的TMMPP问题中,包含了n个数据方{D1,D2,...Dn},其中,每个数据方对应拥有着n个数据{P1,P2,...Pn}。从联邦学习的训练模式来看,在选定好需要进行训练的联邦学习算法后,需为联邦学习提供相应的输入,最终得到训练后的输出。
联邦学习的输入:每个数据方将Pi其拥有的原始数据Di作为联合建模的输入,输入进联邦学习的进程中。
联邦学习的输出:联合所有参与方的数据,联邦训练出全局模型M。
▲联邦学习所遇挑战
联邦学习技术还在持续的完善中。在发展的过程中,联邦学习会遇到三大挑战,他们分别分别是统计挑战、效率挑战、安全挑战。
统计挑战是在联邦学习执行过程中,因为不同用户数据的分布或者数据量的差异造成的挑战;
a)非独立同分布数据,即不同用户数据分布不独立,有明显的分布差别,比如甲方拥有的是中国北方的水稻种植数据,而乙方拥有的是中国南方水稻种植数据,由于纬度,气候,人文等影响,双方的数据是不服从于同分布的;
b)非平衡数据,即用户的数据量有明显的差异,比如巨头企业掌握着近千万的数据量,而小公司仅掌握数万条的数据,两者合作,小公司的数据对巨头企业的影响微乎其微,也难以在模型训练中做出贡献。
效率挑战指的是在联邦学习中各个节点本地计算与通信的消耗造成的挑战;
a)通信开销,即用户节点之间的通信,通常指的是在限定带宽的前提下,各个用户之间传输的数据量的大小,数据量越大,则通信损耗越高;
b)计算复杂度,即基于底层加密协议的计算复杂度,通常指底层加密协议计算的时间复杂度,算法计算逻辑越复杂,消耗时间越多。
安全挑战指的是,在联邦学习过程中,不同的用户使用不同的攻击手段造成信息破解、下等挑战;
a)半诚实模型,即各用户诚实的执行联邦学习中的所有协议,但是会利用获取信息尝试分析并回推他人数据;
b)恶意模型,即存在客户不会严格遵守节点之间的协议,并可能对原始数据或者中间数据进行下以破坏联邦学习进程。
面对以上三大挑战,学术界进行针对性的研究,提出了许多有效的、专用的联邦学习框架来优化联邦学习训练过程。下文我们将对这些框架进行简单介绍。
联邦学习1.0–传统联邦学习
首先,我们重新阐述一下联邦学习的概念与原理:存在若干参与方与协作方共同执行联邦学习任务,参与方通过预置好的联邦学习算法,生成类似于梯度的中间数据,交由协调方进行进一步的处理,随后返还给各参与方,为下一轮的训练做准备。
周而复始,联邦学习任务完成。整个任务中,参与方的本地数据在各个FL框架中并没有参与交换,但协调方和参与方之间传输的参数(比如梯度)可能会泄漏敏感信息。
为了保护数据拥有方的本地数据不被泄露,并在训练过程中保护中间数据的隐私,在FL的框架中应用了一些隐私技术,在参与方与协调方交互时私下交换参数。进一步,从FL框架中使用的隐私保护机制来看,将FL框架分为:
1)非加密的联邦学习框架;
2)基于差分隐私的联邦学习框架;
3)基于安全多方计算的的联邦学习框架;
▲非加密的联邦学习框架
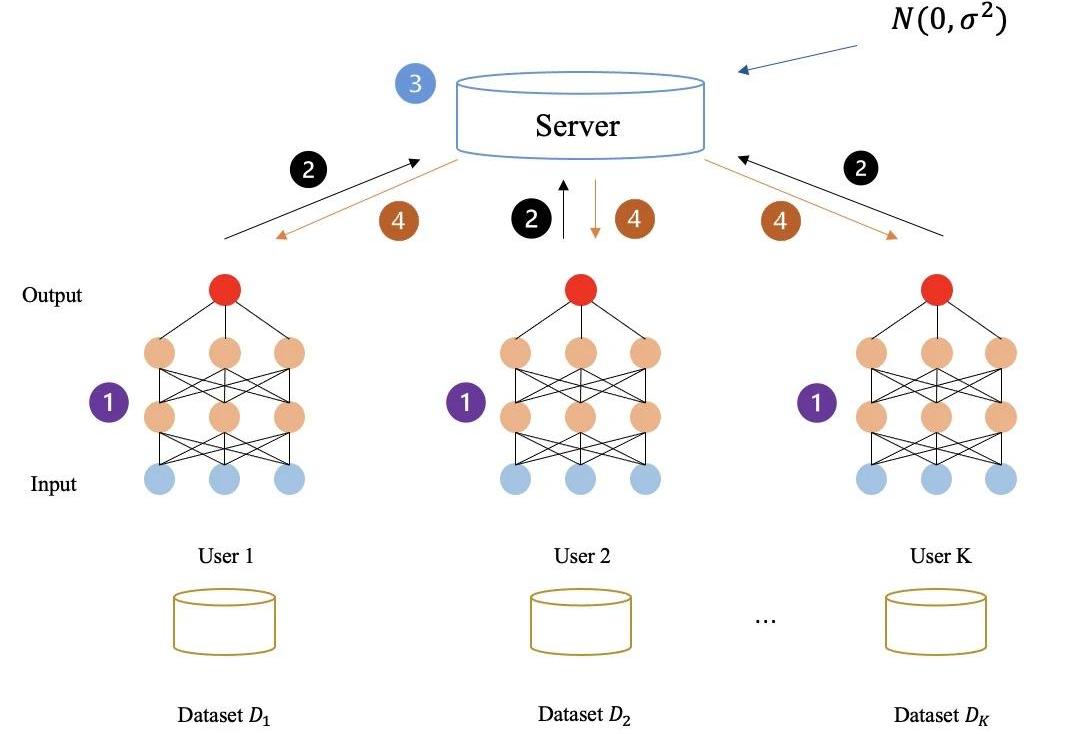
许多FL框架侧重于提高效率或解决统计异质性的挑战,而忽略了交换明文参数所带来的潜在风险。
2015年,由Nishio等人提出的用于机器学习的移动边缘计算框架FedCS,在异构数据属主的设置的基础上,可以快速并高效地执行FL。
2017年,由Smith等人提出了一个名为MOCHA的系统感知优化框架,该框架将FL与多任务学习相结合,通过多任务学习的方式来处理统计挑战中的非同分布数据与数据量差异导致的各种挑战。
同年,梁等人提出了LG-FEDAVG结合局部表示学习。他们表明,局部模型可以更好地处理异构数据,并有效地学习公平的表示,混淆受保护的属性。
下图所示:完全未加密任何中间数据的联邦学习流程,所有的中间数据全是明文传输与计算。通过以上方式,参与方最终共同学习,得到联邦学习模型。
▲基于差分隐私的联邦学习框架
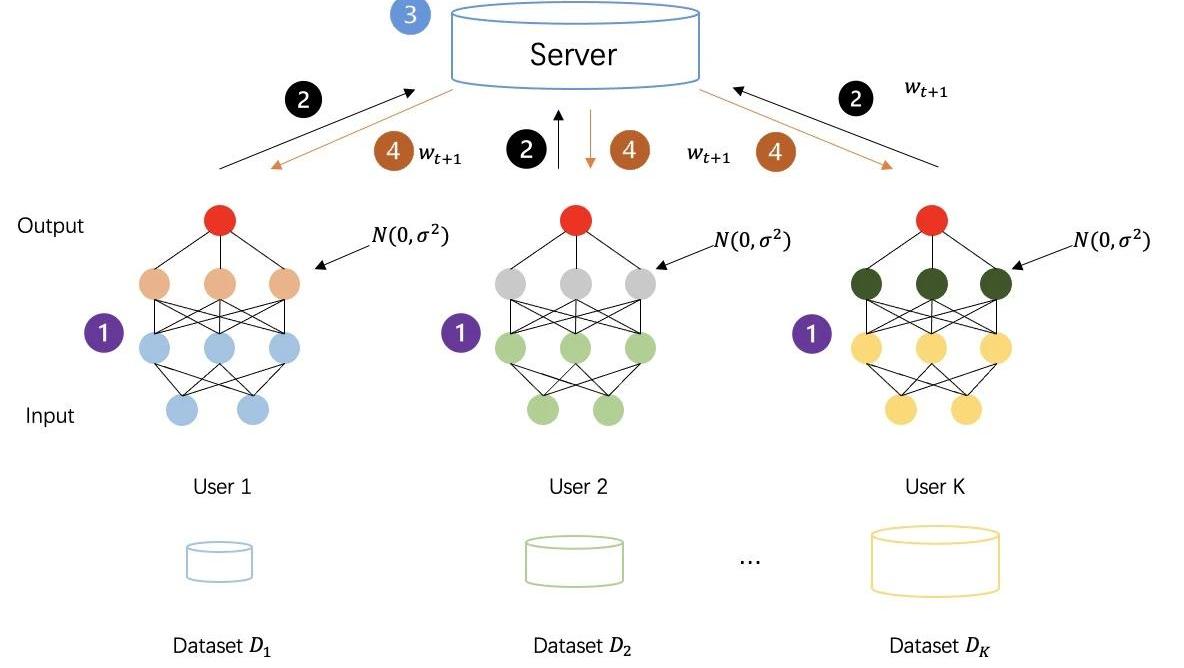
差分隐私是一种隐私技术,具有很强的信息理论保证,可以在数据中增加噪声。满足DP的数据集可以抵抗对私有数据的任何分析,换句话说,所获得的数据敌手对于在同一数据集中推测其他数据几乎是无用的。通过在原始数据或模型参数中添加随机噪声,DP为单个记录提供统计隐私保证,从而使数据无法恢复以保护数据属主的隐私。
下图所示:采取差分隐私对中间数据进行加密后的联邦学习流程,各方生成的中间数据不再是明文传输计算,而是添加过噪声的隐私数据,以此来进一步增强训练过程的安全性。
▲基于安全多方计算的联邦学习框架
在FL框架中,同态加密和安全多方计算等方法得到了广泛的应用,但它们只向参与方与协调方揭示了计算结果,过程中并没有透露任何除计算结果外的额外的信息。
实际上,HE应用于FL框架的方式与应用于安全多方学习框架的方式类似,只是细节上略有不同。在FL框架中,HE用于保护参与方和协调方之间交互的模型参数的隐私,而不是像MPL框架中应用的HE那样直接保护参与方之间交互的数据。在FL模型中应用加法同态来保护梯度的隐私,以提供针对半诚信中心化协调方的安全性。
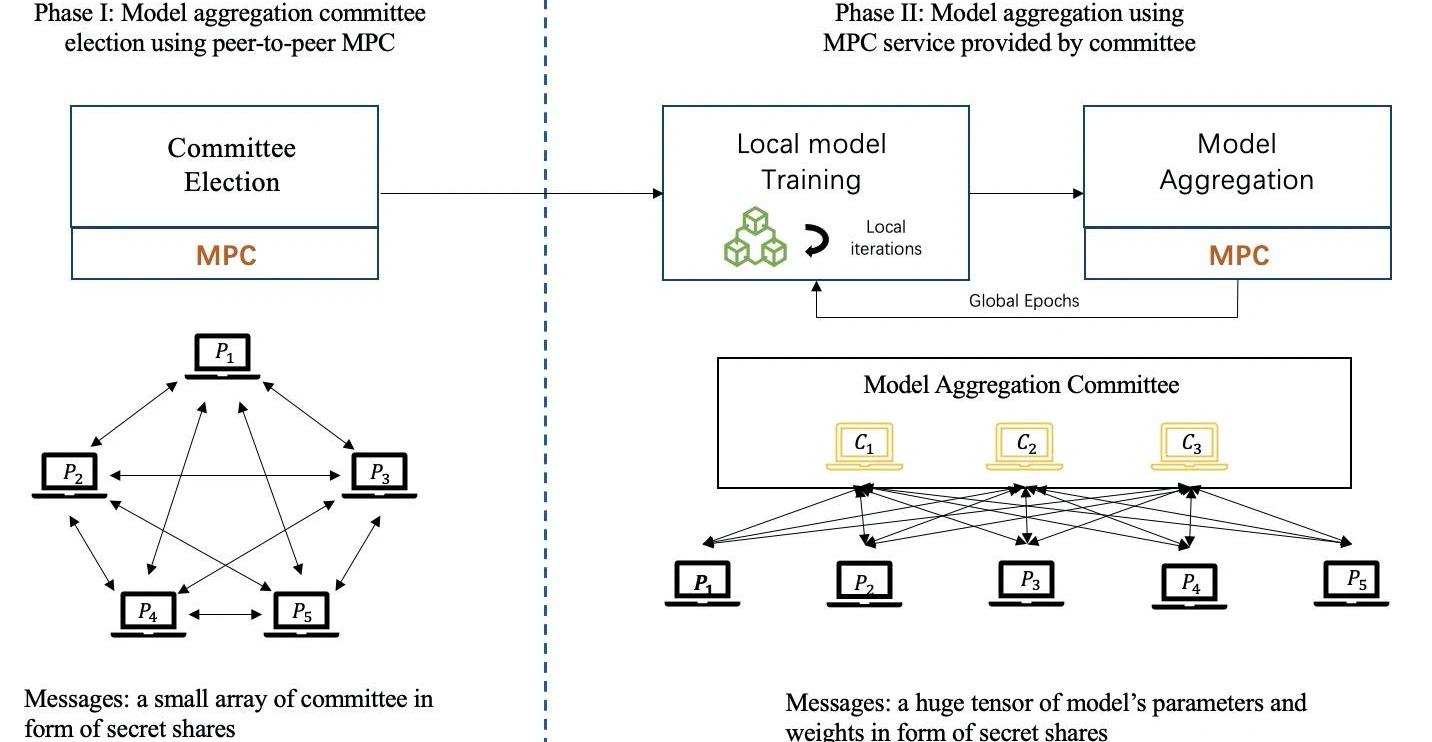
MPC涉及多个方面,并保留了原有的准确性,具有很高的安全性保证。MPC保证了每一方除了结果之外什么都不知道。因此MPC可以应用于FL模型中,用于安全聚合并保护本地模型。在基于MPC的FL框架中,集中式的协调方不能获得任何本地信息和本地更新,而是在每一轮协作获得聚合结果。然而,如果在FL框架中应用MPC技术将会产生大量额外的通信和计算成本。
迄今为止,秘密共享是在FL框架中应用最广泛的MPC基础协议,特别是Shamir的SS。
下图所示:基于MPC的联邦学习训练流程,会由参与方公平的选举出一组委员会成员作为协调方,通过执行MPC技术来协作完成模型聚合的任务。
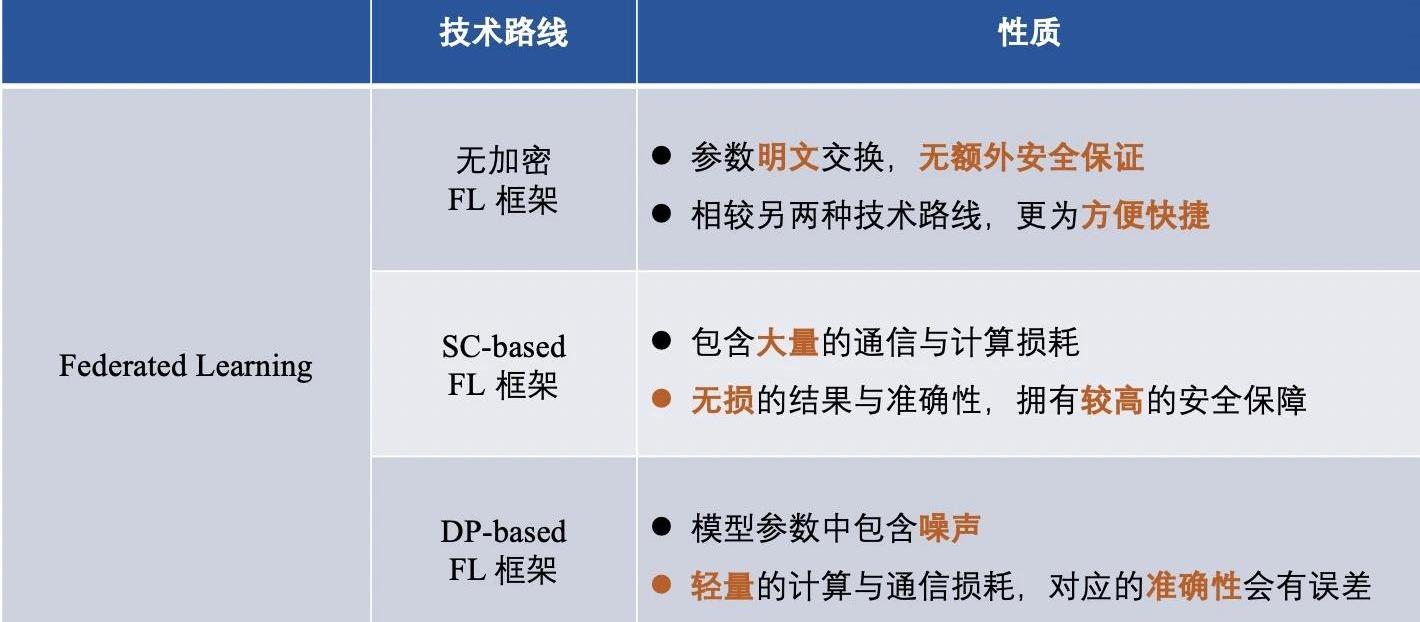
介绍完三种FL框架后,我们总结不同技术路线的框架区别,大体如下:
联邦学习2.0--安全多方学习
上文我们提到到「安全多方学习」,这是基于联邦学习衍生出的一个术语,简单来说就是:没有第三方协作方的联邦学习,被称之为安全多方学习,与先前所介绍的FL区分开来。换言之,在联邦学习的基础上,安全多方学习剔除了传统联邦学习模式中的协调方,并弱化了协调方的能力,将原本的星形网络替换成点对点网络并使得所有参与方的地位相同。
MPL的框架大体分为四类,包括:
1)基于同态加密的MPL框架;
2)基于混淆电路的MPL框架;
3)基于秘密共享的MPL框架;
4)基于混合协议的MPL框架;
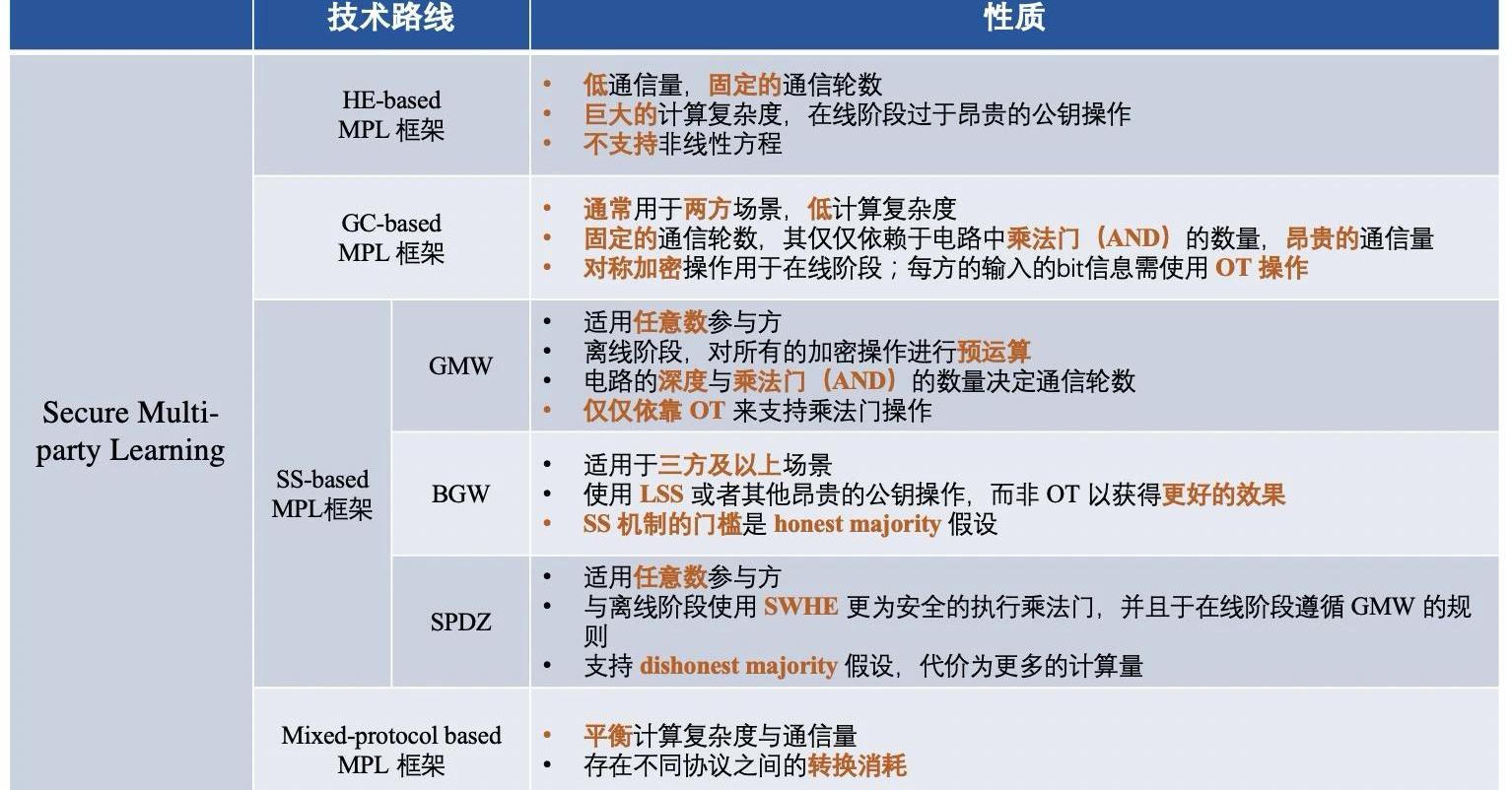
简单来说,不同的MPL框架即为:使用了不同的密码学协议来保障中间数据安全的框架。MPL的流程与FL大体类似,我们一起看一下使用过的四种密码学协议:
▲同态加密
同态加密是一种加密形式,我们可以在不解密,不知道密钥的前提下,直接对密文执行特定的代数操作。然后,它生成一个加密结果,其解密结果与在明文上执行的相同操作的结果完全相同。
HE可以分为「三种类型」:1)部分同态加密(PHE),PHE只允许无限次的一种操作;2)-3)有限同态加密与全同态加密,为了在密文中同时进行加法和乘法SWHE和FHE。SWHE可以在有限次数内执行某些类型的操作,而FHE可以在无限次数处理所有操作。FHE的计算复杂度比SWHE和PHE要昂贵得多。
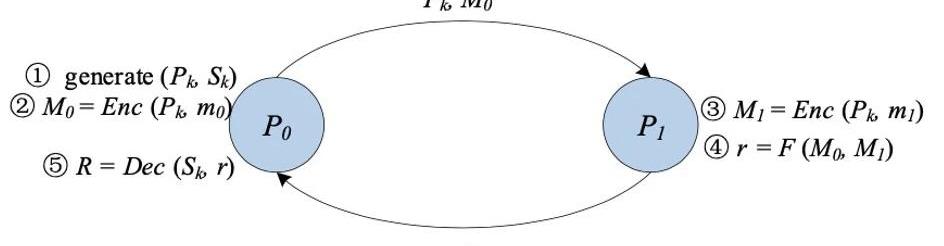
▲混淆电路
混淆电路,又称姚氏混淆电路,是由姚期智院士提出的一种安全的两方计算的底层技术。GC提供了一个交互式协议,让两方(一个混淆者garbler和一个评估者evaluator)对一个任意函数进行无意识的评估,这个函数通常表示为一个布尔电路。
在经典GC的构造中主要包括三个阶段:加密、传输、评估。
首先,对于电路中的每一条线,混淆者生成两个随机字符串作为标签,分别代表该线可能的两个位值“0”和“1”。对于电路中的每一个门,混淆者都会创建一个真值表。真值表的每个输出都是用与其输入相对应的两个标签进行加密。这是由混淆者选择一个密钥推导函数,利用这两个标签生成对称密钥。
然后,混淆者对真值表的行进行换行。在混淆阶段结束后,混淆者将混淆后的表以及与其输入为对应的输入线标签传送给评估者。
此外,评估者通过不经意传输安全地获取其输入对应的标签。有了混淆表和输入线的标签,评估者负责对混淆表进行反复解密,直至得到函数的最终结果。
▲秘密共享
GMW协议是第一个安全的多方计算协议,允许任意数量的一方安全地计算一个可以表示为布尔电路或算术电路的函数。以布尔电路为例,所有各方使用基于XOR的SS方案共享输入,各方交互计算结果,逐门计算。基于GMW的协议不需要对真值表进行混淆,只需要进行XOR和AND运算进行计算,所以不需要进行对称的加解密操作。此外,基于GMW的协议允许预先计算所有的加密操作,但在在线阶段需要多方进行多轮交互。因此,GMW在低延迟网络中取得了良好的性能。
BGW协议是3方以上的算术电路安全多方计算的协议。该协议的总体结构与GMW类似。一般来说,BGW可以用来计算任何算术电路。与GMW协议类似,对于电路中的加法门,计算是可以在本地进行的,而对于乘法门,各方需要交互。但是,GMW和BGW在交互形式上有所不同。BGW不是使用OT来进行各方之间的通信,而是依靠线性SS来支持乘法运算。但BGW依靠的是诚实多数制(honest-majority)。BGW协议可以对抗除t<n/2个腐坏方的半诚实敌手,对抗t<n/3个腐坏方的恶意敌手。
SPDZ是Damgard等人提出的一种不诚实多数制计算协议,它能够支持两方以上的计算算术电路。它分为离线阶段和在线阶段。SPDZ的优势在于昂贵的公钥密码计算可以在离线阶段完成,而在线阶段则纯粹使用廉价的、信息理论上安全的基元。SWHE用于在离线阶段执行constant-round的安全乘法。SPDZ的在线阶段是linear-round,遵循GMW范式,在有限域上使用秘密共享来确保安全。SPDZ最多可以对抗恶意敌手的t<=n个腐坏方,其中t为敌手数量,n为计算方数。
将集中密码学协议进行阶段性总结,不同技术路线对应的框架区别大体如下:
联邦学习3.0--群学习
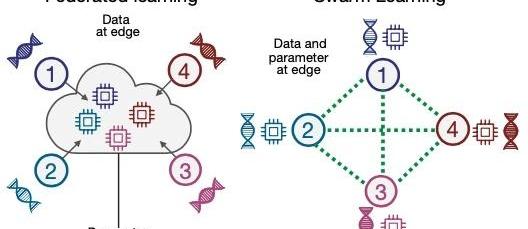
2021年,波恩大学的JoachimSchultze和他的合作伙伴提出了一种名为SwarmLearning的「去中心化机器学习系统」,这是基于MPL进一步的衍化升级,它取代了当前跨机构医学研究中集中数据共享的方式。SwarmLearning通过Swarm网络共享参数,再在各个参与方的本地数据上独立构建模型,并利用区块链技术对试图破坏Swarm网络的不诚实参与者采取强有力的措施。
相较于FL与MPL,SwarmLearning将区块链的技术引入到联邦学习的训练过程中,很好地将区块链取代了公信第三方,起到训练协同的作用。
▲联邦学习技术路线比较
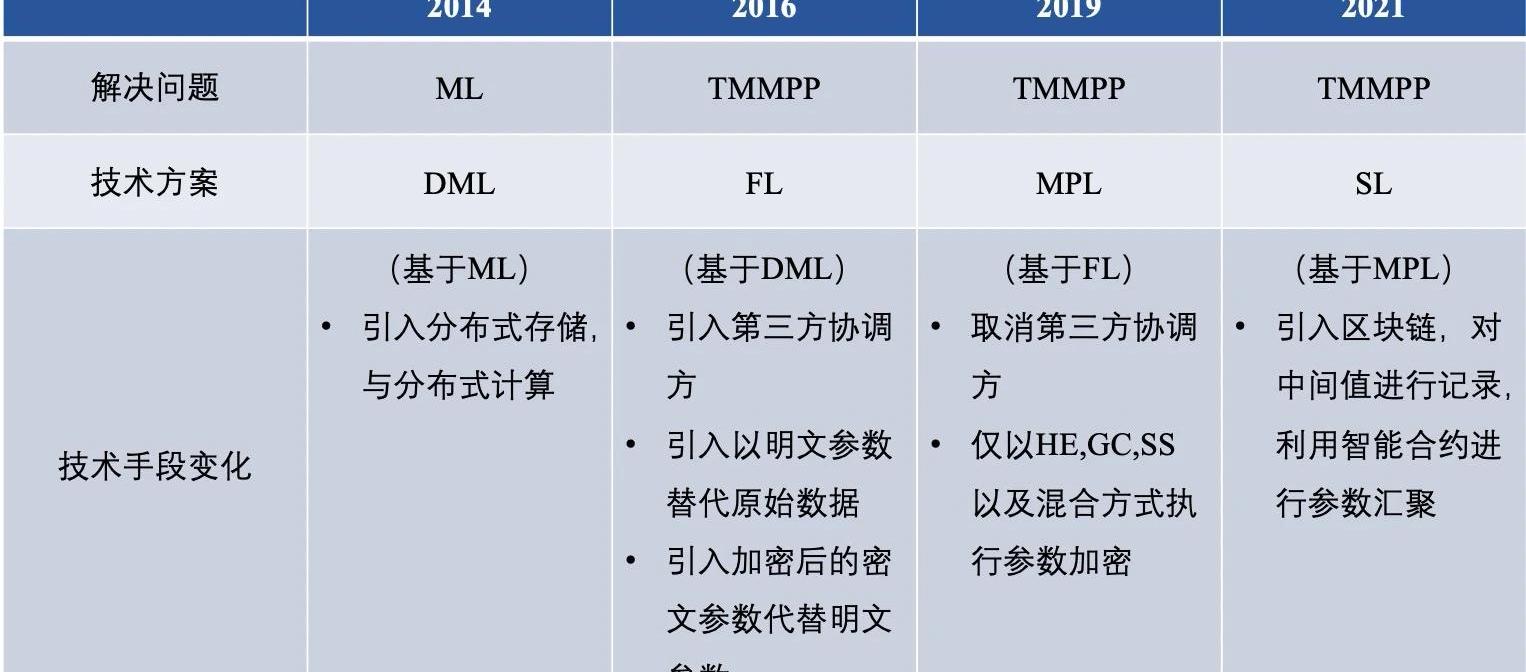
纵观联邦学习的前世今生,其已经拥有了多种解决问题的技术路线,经总结,分布式机器学习,联邦学习,安全多方学习,群学习的差异大体如下:
这其中,我们将传统的FL与MPL进行更深层次的对比,体现在以下六点:
1)隐私保护
MPC框架中使用的MPC协议为双方提供了很高的安全性保证。然而,非加密FL框架在数据属主和服务器之间交换模型参数是明文的,敏感信息也可能被泄露;
2)通信方式
在MPL中,数据属主之间的通信通常是在没有可信第三方的情况下以对等的形式进行的,而FL通常是以具有集中式服务器的Client-Server的形式进行的。换句话说,MPL中的每个数据属主在状态上是相等的,而FL中的数据属主和集中式服务器是不对等的;
3)通信开销
对于FL,由于数据属主之间的通信可以由一个中心化服务器来协调,通信开销比MPL的点对点形式更小,特别是当数据属主的数量非常大时;
4)数据格式
目前,在MPL的解决方案中,不考虑非IID设置。然而,在FL的解决方案中,由于每个数据属主都在本地训练模型,因此更容易适应非IID设置;
5)训练模型的准确性
在MPL中,在全局模型中通常没有精度损失。但如果FL利用DP保护隐私,全局模型通常会有一定的准确性损失;
6)应用场景
结合上述分析,可以发现MPL更适合于安全性和准确性较高的场景,而FL更适合于性能要求较高的场景,用于更多的数据拥有方。
▲联邦学习框架多方比较
自2016年FL基础性框架的内容对比
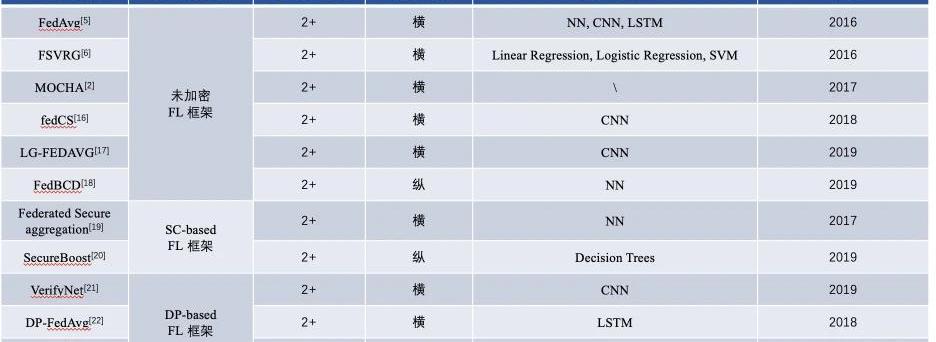
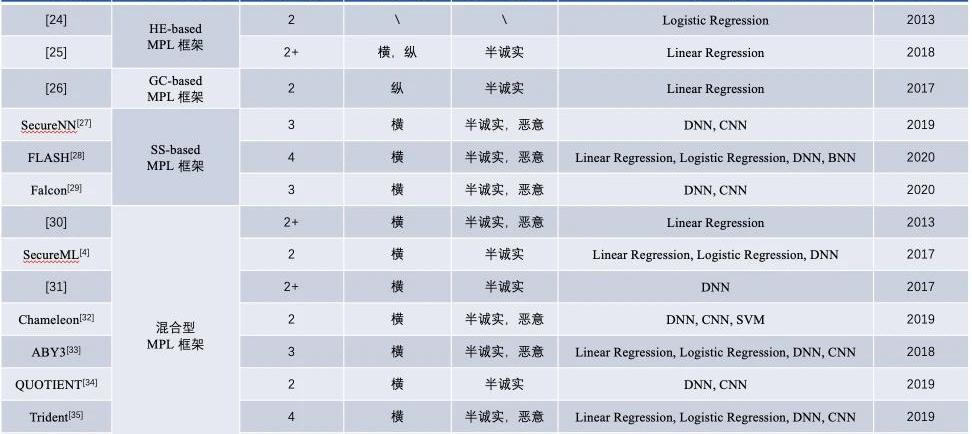
基于FL的MPL基础框架的内容对比
随着联邦学习技术的不断发展,针对不同挑战的联邦学习平台不断涌现,但仍未达到成熟的阶段。目前,在学术界中,联邦学习平台主要解决的问题是非平衡与非同分布的数据问题,而工业界更多的把眼光放在了密码学协议上来解决联邦学习的安全问题。
两边齐头并进,将现有的很多机器学习算法实现了联邦化,但仍不成熟,并未达到可以落地投产的阶段。近几年,联邦学习框架的研究与落地仍处于初级阶段,需要持续不断的努力和推进。
作者简介
严杨联邦学习后驱者
趣链科技数据网格实验室BitXMesh团队
参考文献
P.VoigtandA.VondemBussche,“Theeugeneraldataprotectionregulation(gdpr),”APracticalGuide,1stEd.,Cham:SpringerInter-nationalPublishing,2017.
D.Bogdanov,S.Laur,andJ.Willemson,“Sharemind:Aframeworkforfastprivacy-preservingcomputations,”inProceedingsofEuropeanSymposiumonResearchinComputerSecurity.Springer,2008,pp.192–206.
D.Demmler,T.Schneider,andM.Zohner,“Aby-aframeworkforefficientmixed-protocolsecuretwo-partycomputation.”inProceedingsofTheNetworkandDistributedSystemSecuritySymposium,2015.
P.MohasselandY.Zhang,“Secureml:Asystemforscalableprivacy-preservingmachinelearning,”inProceedingsof2017IEEESymposiumonSecurityandPrivacy(SP).IEEE,2017,pp.19–38.
H.B.McMahan,E.Moore,D.Ramage,andB.A.yArcas,“Feder-atedlearningofdeepnetworksusingmodelaveraging,”CoRR,vol.abs/1602.05629,2016.
J.Konecˇny`,H.B.McMahan,D.Ramage,andP.Richta?rik,“Federatedoptimization:Distributedmachinelearningforon-deviceintelligence,”arXivpreprintarXiv:1610.02527,2016.
J.Konecˇny`,H.B.McMahan,F.X.Yu,P.Richta?rik,A.T.Suresh,andD.Bacon,“Federatedlearning:Strategiesforimprovingcommunica-tionefficiency,”arXivpreprintarXiv:1610.05492,2016.
B.McMahan,E.Moore,D.Ramage,S.Hampson,andB.A.yArcas,“Communication-efficientlearningofdeepnetworksfromdecentral-izeddata,”inProceedingsofArtificialIntelligenceandStatistics,2017,pp.1273–1282.
A.C.-C.Yao,“Howtogenerateandexchangesecrets,”inProceedingsofthe27thAnnualSymposiumonFoundationsofComputerScience(sfcs1986).IEEE,1986,pp.162–167.
V.Smith,C.-K.Chiang,M.Sanjabi,andA.S.Talwalkar,“Federatedmulti-tasklearning,”inProceedingsofAdvancesinNeuralInformationProcessingSystems,2017,pp.4424–4434.
R.Fakoor,F.Ladhak,A.Nazi,andM.Huber,“Usingdeeplearningtoenhancecancerdiagnosisandclassification,”inProceedingsoftheinternationalconferenceonmachinelearning,vol.28.ACMNewYork,USA,2013.
M.Rastegari,V.Ordonez,J.Redmon,andA.Farhadi,“Xnor-net:Imagenetclassificationusingbinaryconvolutionalneuralnetworks,”inProceedingsofEuropeanconferenceoncomputervision.Springer,2016,pp.525–542.
F.Schroff,D.Kalenichenko,andJ.Philbin,“Facenet:Aunifiedembeddingforfacerecognitionandclustering,”inProceedingsoftheIEEEconferenceoncomputervisionandpatternrecognition,2015,pp.815–823.
P.VoigtandA.VondemBussche,“Theeugeneraldataprotectionregulation(gdpr),”APracticalGuide,1stEd.,Cham:SpringerInter-nationalPublishing,2017.
D.Bogdanov,S.Laur,andJ.Willemson,“Sharemind:Aframeworkforfastprivacy-preservingcomputations,”inProceedingsofEuropeanSymposiumonResearchinComputerSecurity.Springer,2008,pp.192–206.
T.NishioandR.Yonetani,“Clientselectionforfederatedlearningwithheterogeneousresourcesinmobileedge,”inProceedingsof2019IEEEInternationalConferenceonCommunications(ICC).IEEE,2019,pp.1–7.
P.P.Liang,T.Liu,L.Ziyin,R.Salakhutdinov,andL.-P.Morency,“Thinklocally,actglobally:Federatedlearningwithlocalandglobalrepresentations,”arXivpreprintarXiv:2001.01523,2020.
Y.Liu,Y.Kang,X.Zhang,L.Li,Y.Cheng,T.Chen,M.Hong,andQ.Yang,“Acommunicationefficientverticalfederatedlearningframework,”arXivpreprintarXiv:1912.11187,2019.
K.Bonawitz,V.Ivanov,B.Kreuter,A.Marcedone,H.B.McMahan,S.Patel,D.Ramage,A.Segal,andK.Seth,“Practicalsecureaggre-gationforprivacy-preservingmachinelearning,”inProceedingsofthe2017ACMSIGSACConferenceonComputerandCommunicationsSecurity,2017,pp.1175–1191.
K.Cheng,T.Fan,Y.Jin,Y.Liu,T.Chen,andQ.Yang,“Se-cureboost:Alosslessfederatedlearningframework,”arXivpreprintarXiv:1901.08755,2019.
G.Xu,H.Li,S.Liu,K.Yang,andX.Lin,“Verifynet:Secureandverifiablefederatedlearning,”IEEETransactionsonInformationForensicsandSecurity,vol.15,pp.911–926,2019.
H.B.McMahan,D.Ramage,K.Talwar,andL.Zhang,“Learn-ingdifferentiallyprivaterecurrentlanguagemodels,”arXivpreprintarXiv:1710.06963,2017.
Y.Zhao,J.Zhao,M.Yang,T.Wang,N.Wang,L.Lyu,D.Niyato,andK.Y.Lam,“Localdifferentialprivacybasedfederatedlearningforinternetofthings,”arXivpreprintarXiv:2004.08856,2020.
M.Hastings,B.Hemenway,D.Noble,andS.Zdancewic,“Sok:Generalpurposecompilersforsecuremulti-partycomputation,”inProceedingsof2019IEEESymposiumonSecurityandPrivacy(SP).IEEE,2019,pp.1220–1237.
I.Giacomelli,S.Jha,M.Joye,C.D.Page,andK.Yoon,“Privacy-
preservingridgeregressionwithonlylinearly-homomorphicencryp-tion,”inProceedingsof2018InternationalConferenceonAppliedCryptographyandNetworkSecurity.Springer,2018,pp.243–261.
A.Gasco?n,P.Schoppmann,B.Balle,M.Raykova,J.Doerner,S.Zahur,andD.Evans,“Privacy-preservingdistributedlinearregressiononhigh-dimensionaldata,”ProceedingsonPrivacyEnhancingTechnologies,vol.2017,no.4,pp.345–364,2017.
S.Wagh,D.Gupta,andN.Chandran,“Securenn:3-partysecurecomputationforneuralnetworktraining,”ProceedingsonPrivacyEnhancingTechnologies,vol.2019,no.3,pp.26–49,2019.
M.Byali,H.Chaudhari,A.Patra,andA.Suresh,“Flash:fastandrobustframeworkforprivacy-preservingmachinelearning,”ProceedingsonPrivacyEnhancingTechnologies,vol.2020,no.2,pp.459–480,2020.
S.Wagh,S.Tople,F.Benhamouda,E.Kushilevitz,P.Mittal,andT.Rabin,“Falcon:Honest-majoritymaliciouslysecureframeworkforprivatedeeplearning,”arXivpreprintarXiv:2004.02229,2020.
V.Nikolaenko,U.Weinsberg,S.Ioannidis,M.Joye,D.Boneh,andN.Taft,“Privacy-preservingridgeregressiononhundredsofmillionsofrecords,”pp.334–348,2013.
M.Chase,R.Gilad-Bachrach,K.Laine,K.E.Lauter,andP.Rindal,“Privatecollaborativeneuralnetworklearning.”IACRCryptol.ePrintArch.,vol.2017,p.762,2017.
M.S.Riazi,C.Weinert,O.Tkachenko,E.M.Songhori,T.Schneider,andF.Koushanfar,“Chameleon:Ahybridsecurecomputationframe-workformachinelearningapplications,”inProceedingsofthe2018onAsiaConferenceonComputerandCommunicationsSecurity,2018,pp.707–721.
P.MohasselandP.Rindal,“Aby3:Amixedprotocolframeworkformachinelearning,”inProceedingsofthe2018ACMSIGSACConferenceonComputerandCommunicationsSecurity,2018,pp.35–52.
N.Agrawal,A.ShahinShamsabadi,M.J.Kusner,andA.Gasco?n,“Quotient:two-partysecureneuralnetworktrainingandprediction,”inProceedingsofthe2019ACMSIGSACConferenceonComputerandCommunicationsSecurity,2019,pp.1231–1247.
R.RachuriandA.Suresh,“Trident:Efficient4pcframeworkforpri-vacypreservingmachinelearning,”arXivpreprintarXiv:1912.02631,2019.
A.PatraandA.Suresh,“Blaze:Blazingfastprivacy-preservingma-chinelearning,”arXivpreprintarXiv:2005.09042,2020.
SongL,WuH,RuanW,etal.SoK:Trainingmachinelearningmodelsovermultiplesourceswithprivacypreservation.arXivpreprintarXiv:2012.03386,2020.
加入PolkaWorld社区,共建Web3.0! 10月6日下午16:50,Kusama网络的第10个平行链插槽拍卖结束!随后进行了40min左右的随机“摇骰子”来决定最后的获胜者.
原地址:https://twitter.com/chaserchapman/status/1457032028667453447?s=21作者:ChaseChapman 翻译:DRD 翻译机构:.
撰文:FootprintAnalytics分析师Amanda 什么是EVM EVM是「以太坊虚拟机」的缩写,是以太坊网络的心脏,是承担智能合约部署和执行的核心.
如果你能够选择出生地,你会选择萨尔瓦多吗?相信圈外的朋友不会,但圈内的朋友可能会。打开微信,搜索“萨尔瓦多”,我惊了。微信好友中竟有多人已经把所在地改为了萨尔瓦多.
我们非常高兴地宣布Chainlink迄今为止规模最大的黑客松正式开放报名!此次黑客松将于2021年10月22日开始,一直持续到11月28日.
顺应国家大力发展区块链的趋势,自2020年以来,全国迎来了区块链政策热潮,中央以及各地方政府纷纷颁布区块链相关政策.