干货 | 为以太坊引入 KZG 承诺:工程师视角(上)
(续前)什么是 KZG10 承诺?
注 3.6:如果启动设置所计算的 [s],[s^2]…[s^d] 只计算到了指数 d,这一组值是不能用来生成任何阶数大于 d 的多项式的承诺的。反之亦然。
因为在安全的曲线上,没有办法用两个点相乘来得出第三个点,所以 [s^(d+k)] 是一个(永远!)无法求出的值,因此可以说,任意的承诺 c(f) 都只能表示一个阶数小于等于 d 的多项式。
注 3.7:使用 KZG10 承诺的证据基本上就是在证明 f(x) - 某些余数 的结果可以按特定的办法来分解,但这就要有一种办法可以 相乘 这些因数,并与原始的承诺相比较 C(f)=f([s])。
为此,我们需要 “配对方程”,就是一种能把曲线上的两个点相乘并与另一个曲线点比较的乘法,因为我们无法直接让这两个曲线点直接相乘来得到合成的曲线点。
注 3.8:上述两个属性,可以进一步用来证明某个承诺 c(f) 所代表的多项式 f(x) 的阶数 k 小于 d。
综上,KZG10 承诺可以有很好的属性:
验证承诺的过程是:(由区块生成者)提供底层多项式在任意点 r 上的值 y=f(r) ,以及除法多项式 q(x)=(f(x)-y)/(x-r) 在 [s] 点的值(即 q([s])),并用 配对方程 来对比之前所提供的承诺 f[s]。这就叫 开启 在 r 点的承诺,而 q([s]) 就是证据。容易看出,q(s) 就是 p(s)-r 除以 s-r ,恰好就是我们用配对方程来检查的东西,即检查 (f([s])-[y]) * '= q([s]) * [s-r]' (译者注:此处疑为 f(s)-r ,但原文就是 p(s)-r)。
在非交互且确定性的版本中, Fiat Shamir Heuristic 提供了一种办法来获得相对随机的点 r:因为随机性只跟我们尝试证明的输入有关,即,只要已经有了承诺 c=f([s]) ,r 就可以用哈希所有输入(r=Hash(C,..))来获得,而 承诺的提出者 要负责提供 开启点 和 证据。
使用预先计算好的拉格朗日多项式,f([s]) 和 q([s]) 都可以在 求值形式 下直接计算。要计算 r 处的开启值,就需要把 f(x) 转为 f(x)=a0+ a1*x^1.... 的系数形式(也即抽取出 a0、a1、…)。可以通过 反向快速傅立叶变换 来实现,复杂度为 O(d log d),但甚至这里也有一种可用的替代算法,在 O(d) 的复杂度内完成计算,而无需使用反向快速傅立叶变换。
你可以使用单个开启点和证据来证明 f(x) 的多个值,也就是多个索引值对应的数值, index1=>value1、index2=>value2 …
(用于计算证据的)除法多项式 q(x) 现在变成了 f(x) 除以零多项式 z(x) =(x-w^index1)*(x-w^index2)...(x-w^indexk) 的商
CoFiX将于7月29日在主网上线CoFiX v2.1版:据官方消息,可计算金融协议将于7月29日在主网上线CoFiX v2.1版本,届时将启用新的资金池地址,增加新的做市交易对。流动性提供者可在升级前将资产从资金池赎回,并领取COFI奖励,等待升级完成后,再存入资金池做市。
CoFiX是基于EPM(均衡定价模型)及NEST预言机设计的DEX,具备无价格滑点、全市场深度及风险可计算等特点。[2021/7/28 1:21:09]
余数为 r(x) ( r(x) 是一个最大阶数为 k 的多项式,由 index1=>value1, index2=>value2 … indexk=valuek 插值而成)
检查 ( f([s])-r([s]) )* ' = q([s]) * z([s]')
在 PoS 链的共同起步设置中,共享的数据块会被表示为低阶的多项式(并为了 纠删码 而使用同样的 拟合 多项式扩展为两倍大),KZG 承诺可以用来检查任意 随机 分块并验证和确保 数据可得性,而无需获得 兄弟数据点。这就开启了随机取样的可能性。
现在,对于一个最大可能包含 2^28 个账户键的状态,你需要至少 2^28 阶的多项式来构建 扁平的 承诺(flat commitment)(实际上的账户键总空间会大得多得多)。在更新和插入的时候,会有一些不便利。对任一账户的任意更改,都会触发承诺(以及更麻烦的,见证数据/证据)的重新计算。
更新 KZG10 承诺
对任一 索引值 => 数值 点的任何更改,比如更改了 indexk,都需要使用相应的拉格朗日多项式来更新承诺。复杂度约为每次更新 O(1)。
但是,因为 f(x) 本身也改变了,所以所有的见证 q_i([s]) ,也即所有对第 i 个键值对的见证,也需要更新。总复杂度约为 O(N)
如果我们没有维护预先计算好的 q_i([s]) 见证,任何一条见证数据都要从头开始计算,都需要 O(N)
一种复杂度为 sqrt(N) 的更新 KZG10 承诺的构造
因此,为了实现理想承诺方案的第四点,我们需要一个特殊的构造:Verkle trie。
需要表示的以太坊的状态大约有 2^28 约等于 16^7 约等于 2.5 亿 个键值对。如果我们只使用扁平的承诺(那么我们需要的阶数就至少是 2^28)。虽然我们的证据永远是 48 个字节的椭圆曲线元素,但任意的插入或更新,都需要 O(N) 次操作来更新所有预先计算好的见证数据(也就是所有点的 q_i(s) ,因为 f(x) 本身已经改变了);甚至于,如果没有预先计算好的见证数据,则每条见证数据都需要花 O(N) 来重新计算。
因此,我们需要把扁平的结构换成叫做 Verkle 树 的结构,跟默克尔树一样是树结构。

即,像默克尔树一样,构建出一棵承诺树,这样我们就可以保证阶数 d 比较小(但也需要高达约 256 或者 1024)。
每个父节点都编码对其子节点的承诺,子节点就是一个映射,其索引值都存在其父节点内
实际上,父节点的承诺编码了哈希后的子节点,因为承诺的输入是标准化的、32 字节的值(见上文的 注3.0)。
叶子节点编码了对其所存储的数据的 32 字节哈希值的承诺;或者直接跳转到数据,假如其 32 字节的数据的用法与下一章提到的 状态树 提议用法一样的话。
要提供对一个分支的证据(类似于默克尔分支证据)时,一个多值证明的承诺 D、E 可以围绕使用 fiat shamir heruristic 产生一个相对随机的点 t 来生成。
复杂度
这里是一份对 Verkle 多值证明的分析
更新/插入 叶子节点 index=>value 需要更新 log_d(N) 个承诺 ~ log_d(N)
为生成证据,证明者需要
计算 f_i(X)/(X-z_i) 在 [s] 处的值,用于生成 D ,复杂度总计 O(d log_d N),但可以在 更新/插入 时调整以节约预计算,复杂度会变成O d log_d(N)
计算 m 个 ~ O( log_d(N) ) 个 f_i(t) 来计算 h(t),总计为 O (d log_d N)
计算 π, ρ ,需要对 m~ log_d N 个指数多项式的和做除法。需要约 O(d log_d N) 来获得分子的求值形式,以计算除法
证明的规模(包括用于计算 E 的分支承诺)加上验证的复杂度 ~ O( log_d(N) )
被提议的 ETH 状态 Verkle 树
单一的树结构,存储账户的 header 和 代码分块,还有 存储项分块,节点的承诺为阶数 d=256 的多项式
把地址和 头/存储空档 结合起来推导出一个 32 字节的 storageKey,本质上就是元组 (address,sub_key,leaf_key) 的一种表示
所推导的键的前 30 个字节用于构建普通的 verkle 树节点 pivots
后 2 个字节是一个树高为 2 的子树,表示最多 65536 个 32 字节的分块
对于基本的数据,这个树高为 2 的子树最多有 4 个叶子承诺,来覆盖 haeader 和 code
因为一个分块为 65536*32 字节的分块表示为单个的字数,所以主树上可能有许多子树来存储一个账户
Gas 定价方案
访问类型 (address, sub_key, leaf_key) 的事件
每一个专门的访问事件都收取 WITNESS_CHUNK_COST
每个专门的 address,sub_key 组合都收取额外的 WITNESS_BRANCH_COST
代码默克尔化
代码会自动成为 verkle 树的一部分(作为统一的状态树的一部分)
一个区块的 header-qjnu 和 code 都作为一个树高为 2 的承诺树的一部分
单个分块最多有 4 条见证数据,分别收取 WITNESS_CHUNK_COST,访问账户需要收取一次 WITNESS_BRANCH_COST
ETH PoS 的目标之一是能够提交约 1.5MB/s 的数据量(把这个吞吐量理解为状态变更的吞吐量,因而是 L2 rollup 可以利用的交易吞吐量,最终是 L1 EVM 的吞吐量)。要实现这一点,许多并行的区块提议要能发出并在给定的 12 秒内验证;也就是要存在多条分片(约 64),每个分片在每个 slot 都要发布自己的数据块。若有大于 2/3 的投票支持,信标链区块将包含分片数据块,分叉选择规则也将根据信标链区块内所有数据块及其祖先的数据可得性确定它是否能成为主链区块。
注 3:此时的分片不是链,任何隐含的顺序都要由 L2 协议来解释。
KZG 承诺也可以用来构建数据有效性和可得性方案,客户端无需访问分片提议者发布的完整数据就可以校验其可得性。
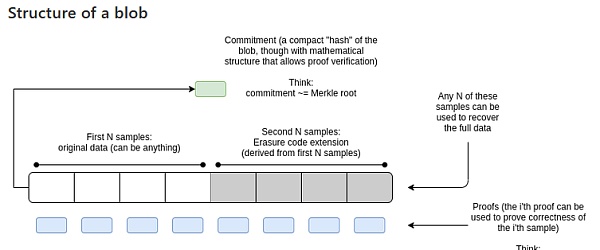
分片数据块(不带纠删码)是 16384 个样本(每个 32 字节),约为 512 kb;还有数据头,主要由这些样本相应的最大 16384 阶的多项式承诺组成
但多项式求值形式 D 却有 2^16384 的规模,即,1,w^1,…w^,… w^32767,而 W 是 32768 的单元根(不是 16384 的)
我们可以为数据(f(w^i)=sample-i for i<16384)拟合出最大 16384 阶的多项式,并扩展到 32768 作为纠删码样本,即计算 f(w^16384) … f(w^32767)
对每个点的值的证明也同时计算并与样本一起发布
32768 个样本中获得任意 16384 个都可以完全恢复出 f(x) 以及原始的样本,即 f(1),f(w^1),f(w^2)… f(w^16383)
这纠删编码的 32768 个样本分为 2048 个分块,每个分块包含 16 个样本,即 512 字节的数据;由分片提议者水平地发布,即将第 i 个分块以及相应地证据发给第 i 个垂直子网络,外加全局公开完整数据的承诺
在被指定的 (shard, slot),每个验证者都在 k~20 个垂直子网中下载和检查这些分块,并使用对应数据块的承诺来验证它们,以建立数据可得性保证
我们需要为每个 (shard, slot) 安排足够多的验证者,使得总体上一般(乃至更多的数据)都被获取了;另外,还要满足一些统计学上的要求,每个 (shard, slot) 约 128 个委员,需要有至少 70 个(也即 2/3 )委员的见证,使得该分片数据块能成功打包到信标链上,
至少需要约 262144 个验证者(32 个 slot,乘以 64 个分片,再乘上至少 128 个委员)
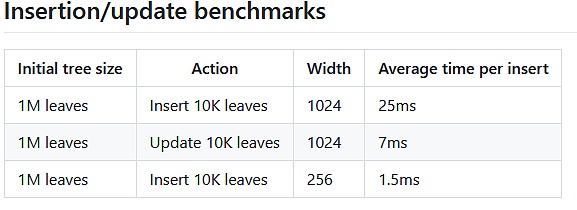
如我们在 POC verkle go 代码库中看到的,以状态树的规模构建完一次 verkle 之后,插入和更新都非常快:
插入/更新 的基准测试
证明生成验证的基准测试

标签:比特币INDEXVERERK比特币交易所有哪些Bitcoin Volatility Index TokencarVerticalTERK币
密码学货币圈子内外,越来越多人寄希望于权益证明(Proof-of-stake,PoS)既能为我们贡献密码学货币的优点、又能避免工作量证明(Proof-ofwork,PoW)的耗能属性。
原文标题:《央行数字货币实施的最优国家检测及对支付行业开放创新的启示》 数字货币的出现及其与央行支持的货币的竞争所带来的威胁已经唤醒了世界各国央行对数字货币的兴趣。因此,本文的目的是阐明什么样的国家最适合实施由中央银行支持的数字货币,即俗称的中央银行数字货币。中国人民大学金融科技研究所(微信ID:ruc_fintech)对文章核心内容进行了编译。
加密货币行业从业人士总在说,2020-2021年这一波比特币大牛市是机构牛。 比如灰度比特币信托持有的比特币从2020年初的10多万持续增加到60多万枚,MicroStrategy持续投入近30多亿美元买入比特币,特斯拉一度买入15亿美元的比特币。 2021年6月,主权国家萨尔瓦多更是立法将比特币作为法定货币。
"拜登政府「影子内阁」BlackRock 正在增加自己的「加密」话语权。" Pitchbook 近段时间的一组数据显示,风险投资基金今年前半年已经向加密领域的公司投资了 170 亿美元。这个资金量代表着,这一年已经成为历史上单年筹集资金最多的一年,且几乎等于前几年筹集资金总额的总和。 在这背后,来自华尔街的机构们功不可没。
1.四川发布禁令后 中国BTC算力大幅下降 来自BTC.com的数据显示,在过去24小时内,15个实时算力最强比特币矿池哈希算力几乎都出现了显著下降,有些甚至下降了46%。
微策略以4.89亿美元购入13005枚BTC,现在总共持有105085枚BTC。 微策略宣布以大约4.89亿美元现金收购13005枚BTC,本次购买平均价格约为37617美元,其中包括手续费和各项费用,目前持有105085枚BTC,平均每个BTC花费26080美元,该公司CEO为长期看好BTC的Michael Saylor。